V
主页
京东 11.11 红包
YOLO V6卷土重来,开源了3.0版本!检测性能超过YOLOX以及PP-YOLOE,达到YOLO系列新SOTA!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
B站【最全YOLO系列】教程,全套36集付费内容,公认最适合新手入门YOLOv11目标检测实战系列,绝对通俗易懂好上手!深度学习_物体检测-人工智能/计算机技术
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
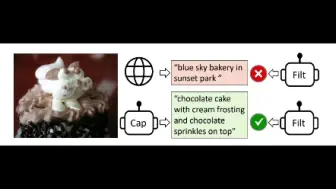
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
Absolute Win!3行代码修复Transformer 位置编码插值bug!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
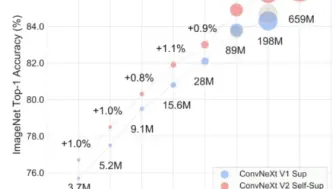
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
微软提出简单的Open vocabulary检测和分割框架,能够统一处理两种任务,性能超过GLIP等模型!目前已开源!
YOLOv5零基础入门!博导耗时10小时精讲YOLOv5从环境配置到项目实战,带你快速训练自己的数据集!
图灵机得主Hiton极力推荐的谷歌深度学习调参手册及中文翻译版来了,包含30页调参技巧,需要的同学快来领取!
SAM+扩散模型让图片中的对象动起来!腾讯提出RegionMaker!
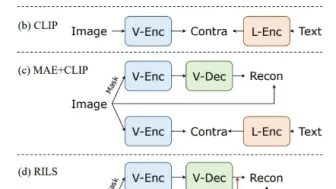
腾讯结合了MAE和CLIP,提出了新的在语言语义上进行掩码重建的预训练框架RILS,超过多种视觉预训练和多模态预训练方案!
几秒钟完成图像定制化生成!清华联合腾讯提出无需微调的AIGC新框架!
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
草履虫都能学会!十天学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等十大深度学习神经网络!学不会你来打我!人工智能/pytorch
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
字节提出新的多边形战士,通用基础模型X-FM,将视觉,文本和多模态的训练做到了一个阶段,在多项下游任务表现不错!
【YOLOv11速通】迪哥13分钟教你使用自己的数据集从环境搭建到模型训练、推理、导出一条龙实操,入门到精通!-YOLO/目标检测/人工智能/计算机视觉
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
Transformer+目标检测:CV领域超好出论文的方向!源码复现+模型精讲+论文解读,迪哥带你轻松搞定论文创新点!DETR/YOLO/计算机视觉
【唐宇迪带你学AI】更新到v11!2024最新版目标检测YOLO算法全系列,从v1到v11一次学到饱,简直不要太爽!
超过IP-Adapter!中科大提出超保真ID个性化AIGC新方法Infinite-ID!
DETR目标检测算法源码解读:YOLO卷不动了,来试试DETR!Transformer跨界CV做检测的开山之作!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
阿里提出了一种联合多个语义分割数据集进行训练的语义分割方法LMSeg,相比单一数据集训练提升明显!
百度联合VIS提出新的文档图像理解预训练框架StrucTextv2,设计了适用于文档数据的掩码自监督策略,目前已被ICLR 2023接收!
斯坦福学者提出ControlNet,通过对Stable Diffussion生成结果进行控制,即将补完AIGC工业化的最后一块拼图!
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
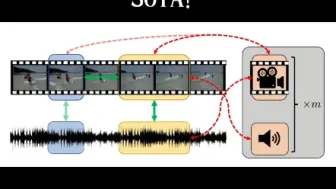
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
CLIP助力跨域目标检测,来自EVEN CVLab的学者提出语义增强策略,提升效果明显
[理解和生成]的大一统,微软提出BLIP多模态模型,取得下游多项任务SOTA!
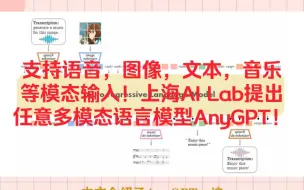
支持语音,图像,文本,音乐等模态输入!上海AI Lab提出任意多模态语言模型AnyGPT!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
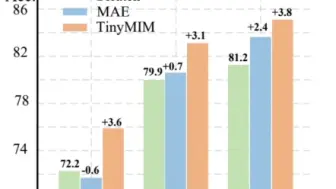
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
YOLOv8实战PCB电路板缺陷检测
阿里提出了一种无需解码头的轻量化语义分割网络,参数量减少30%的同时性能提升4个百分点!
商汤科技提出具有双层路由注意力的视觉Transformer,减少原始ViT计算量的同时性能大幅超过Swin Transformer!已被CVPR 2023接收!
【强推】草履虫都能学会!OpenCV+YOLO 实时目标检测,计算机视觉方向从零到实战,带你做毕设!(深度学习丨计算机视觉丨YOLO丨OpenCV)
微软提出了新的模型蒸馏策略G2SD,利用掩码自动编码器结合特征蒸馏和KD蒸馏,学生模型的精度达到教师模型的98%!目前已开源!