V
主页
[理解和生成]的大一统,微软提出BLIP多模态模型,取得下游多项任务SOTA!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
【多模态+大模型+知识图谱】2024最好创新的研究方向!绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
字节提出新的多边形战士,通用基础模型X-FM,将视觉,文本和多模态的训练做到了一个阶段,在多项下游任务表现不错!
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
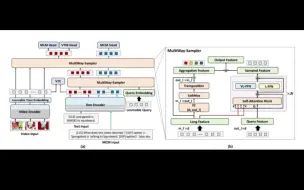
阿里提出用于视频文本理解的高效多模态模型MuLTI,通过设计了Multiway Sampler和多项选择建模任务 在多项视频理解任务上达到新SOTA!
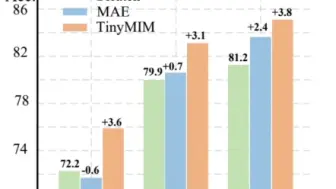
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
华为诺亚实验室提出NLIP多模态模型:仅用2900万数据性能超过BLIP和CLIP等亿级数据训练的多模态模型!
Stability AI又放大招了!基于SD3蒸馏更快的文生图模型SD3-Turbo!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
给多模态加Buffer,GNN在视觉语言下游任务的应用综述来了!包含125篇相关论文,涉及Image Captioning,VQA,Retrieval三大方向!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
谷歌基于掩码Transformer提出新的以文生图SOTA模型Muse!生成效果和效率大幅超过Difussion模型和自回归模型!
微软学者整理了100页图文多模态预训练综述,涉及各种多模态模型和应用,并且附带视频教程,需要的同学快来领取!
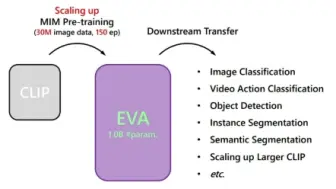
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
面壁 MiniCPM-V 2.6:最强开源端侧多模态 LLM
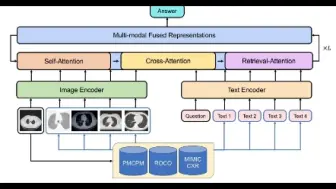
阿里联合清华提出了用于医学VQA的新方法RAMM,利用检索增强的策略在医学VQA数据集上取得新SOTA!数据集,代码即将开源!
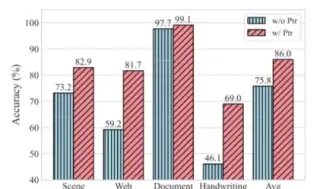
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
继EMO之后又火了!阿里提出Image-to-Video新框架AtomoVideo!
【多模态+知识图谱】半天居然就跟着博士从零构建知识图谱!基于知识图谱的六大项目实战!医药问答系统、知识抽取、推荐系统、Neo4j数据库、大模型
微软提出简单的Open vocabulary检测和分割框架,能够统一处理两种任务,性能超过GLIP等模型!目前已开源!
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
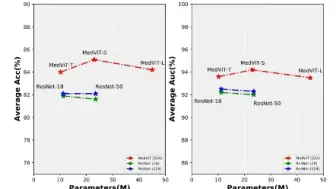
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
SAM+扩散模型让图片中的对象动起来!腾讯提出RegionMaker!
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
1分钟内快速完成学术润色,全网最简易论文润色教程来啦!
超过IP-Adapter!中科大提出超保真ID个性化AIGC新方法Infinite-ID!
阿里达摩院提出新的视频文本预训练框架,通过预训练,其在视频下游任务取得多项SOTA!
亚马逊联合牛津提出了用于多模态理解的三元对比学习TCL,在CLIP的基础上提升了多模态模型的跨模态理解能力!
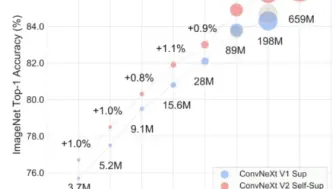
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
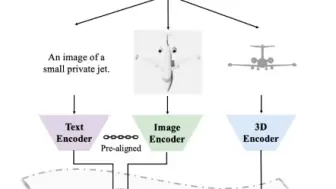
3D版CLIP横空出世,助力各种点云任务!涨点效果明显!
UCSB学者提出了一种利用知识增强来对现有大型语言模型进行解释的新方法,为语言模型提供了人类可理解的解释!
华为诺亚提出开放域检测新方法DetCLIP,推理效率较GLIP推理效率提升20倍!同时利用wordnet进一步提升了开放词汇的检测性能!
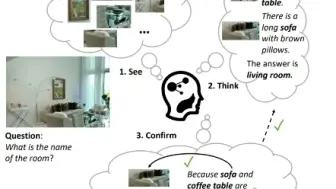
MIT联合清华提出基于知识的视觉推理多模态模型IPVR,模拟人类视觉推理,取得较好效果!
字节联合浙大提出新的视频语言预训练模型TemPVL,能够显著提升下游多模态视频理解任务性能!