V
主页
京东 11.11 红包
UIUC学者发现冻结LLM中的Transformer是有效的视觉编码器层!多项视觉任务性能均有提升!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
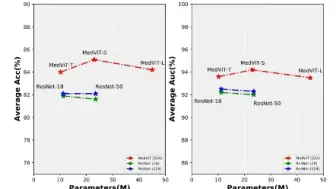
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
腾讯联合浙大提出新的视觉Transformer网络CrossFormer,参数量更少同时性能超过Swin!目前已开源!
商汤科技提出具有双层路由注意力的视觉Transformer,减少原始ViT计算量的同时性能大幅超过Swin Transformer!已被CVPR 2023接收!
深度学习研一,三个月流水线一般发论文教程。
全新的全卷积视觉骨干网FCViT,超过ConvNext,目前已开源!
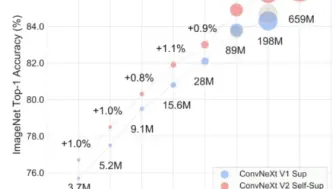
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
Self-Attenion的重思考,VIT更快的同时性能更强,Skip Attention通过减少注意力来提升VIT性能!
DeepMind提出De-Diffusion,仅使用图像数据提升多项多模态任务性能!
亲测50帧!无需内参!超越Dust3r!Spann3r:无需优化对齐快速进行3D重建!
即插即用特征融合模块CAFM,即用即涨点
AI新作 | FlashTex: 快速高质量纹理生成
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
液体神经网络:赶超Transformer!刷新SOTA!
一文讲清楚CUDA
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
比刷剧还爽!2024最新【AI Agent】大模型落地实战教程!58集干货讲解,就怕你不学!(LLM丨langchain丨人工智能丨机器学习丨深度学习神经网络)
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
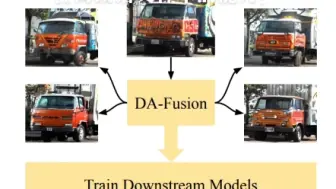
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
一个神级代码复现网站,里面99%的论文都能找到!
打死我也不删的绘图神器!一个神级科研图表网站,可以生成69种精美论文图表!
一个动画讲清楚:大模型思维链复杂度的底层逻辑
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
吹爆!00后勇闯字节算法岗,已拿offer,哪些没人告诉你的面试真相,帮你迅速提升面试通过率!!
直接使用git pull拉代码,被同事狠狠diss了!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
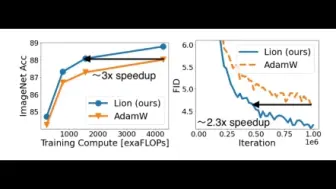
最强优化器来了!谷歌提出适用于多种任务的新型优化器Lion,在多项任务上以更快的训练速度取得更好的性能!目前已开源!
【算法精讲】长短期记忆网络LSTM到底在干啥?(35分钟搞懂原理及代码)
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
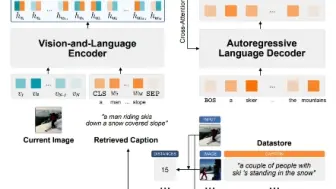
里斯本大学学者提出检索增强的Image Captioning 方法,可以在预训练图文编码器的基础上进一步提升Caption性能!
可解释聚类又“炸出圈”啦!把准3个切入点言路开挂,11种创新思路一学就会~
阿里提出了一种无需解码头的轻量化语义分割网络,参数量减少30%的同时性能提升4个百分点!
一天写完开题报告、文献综述!国内外研究现状怎么写?
《权力的游戏》最终季 AI版 平复粉丝的意难平
打死我也不删的绘图神器!一个神级科研图表网站,可以生成69种精美论文图表!
识别任何区域!字节提出新的万物检测模型RegionSpot!
苹果公司学者提出最快的ViT结构FastViT,实现了效率和精度的trade-off。比Efficient 快5倍,比ConvNext快2倍!
【文献是你最好的老师】研究生如何保持每天看文献的习惯?导师夸爆我的读文献方法!
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!