V
主页
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
【Transformer+UNet】医学图像分割创新最容易复现的3个通用模块—附论文及代码
ai聊天 无敏感词无限制畅聊,支持自定义创建及语音,支持安卓、iOS端!
视觉Transformer喜提金字塔结构:多阶段Token聚合,复杂度超低! CV任务变得更简单了!
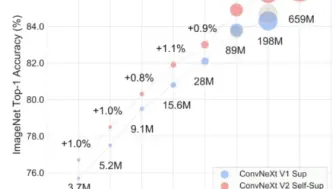
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
超好用的可视化工具,“透视”Transformer
卷不动transformer改进?第三代神经网络-脉冲神经网络了解一下,适配时序、图像各任务,能耗降低54%
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
AI可解释性综述来了,神经网络的黑盒性质经常被许多学者Diss,而可解释性方法让AI不在是完全黑盒!
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
【即插即用】时间序列+注意力模块的创新,让预测误差狂降36%,模型性能和准确性飙升!
UIUC学者发现冻结LLM中的Transformer是有效的视觉编码器层!多项视觉任务性能均有提升!
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
[NeurIPS 2023] 通过Adapter重组实现用于大型视觉Transformer的LORA!!
GNN+Transformer再突破:准确率提升79.49%,内存消耗减少39倍!来看34种创新思路
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
9位Science院士联名发表人工智能发展长篇综述,涵盖了智能计算的基础理论,智能计算融合的重要应用和挑战!
手把手带你完成【猫狗识别实战】这是我见过最适合新手学习的深度学习实战教程!基于TensorFlow+CNN实现猫狗识别_AI/人工智能/深度学习/神经网络
CV研究生必看!基于Transformer的医学图像分割实战,论文解读+源码复现,迪哥带你轻松搞定论文创新点!
用Excel理解神经网络!AI by Hand!大佬手搓Transformer!——神经网络/Transformer/深度学习/机器学习
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
如何简单、通俗的理解Transformer?
ECCV'24开源 | LocoTrack: 塑造SLAM新纪元!6倍加速! 跟踪一切最新SOTA!
全新的全卷积视觉骨干网FCViT,超过ConvNext,目前已开源!
我敢说学习【NLP自然语言处理】只要看这个就够了,NLP中最重要的核心内容,不愧是大家一致仍可的教程-人工智能/机器学习/深度学习
很适合新手用来学习的Transformer工具!超想分享给大家! -神经网络/Transformer/AI by Hand/神经网络入门
时间序列预测 | Autoformer 简介
什么是卷积?强推!这绝对是全网最通俗易懂的【卷积神经网络教程】!草履虫听了都点头!人工智能、深度学习、机器学习
CVPR2023 基于掩码的视觉和语言Transformer,能够同时完成以文生图和Image Captioning两种多模态生成任务,且效果非常不错!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
苹果公司学者提出最快的ViT结构FastViT,实现了效率和精度的trade-off。比Efficient 快5倍,比ConvNext快2倍!
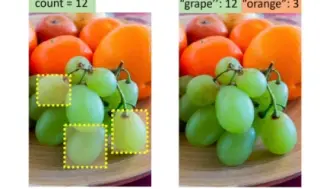
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
想要通俗易懂地理解Transformer?这本大模型黑书是你的不二选择!
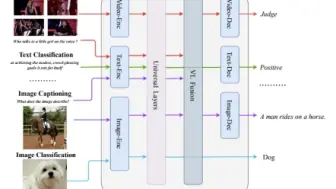
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
深度学习380页详细版综述教程来了!包含CNN,Transformer,GNN,GAN,Difussion Model等热门网络!
世界首例GPT植入活人大脑,碾压马斯克脑机接口!
今天给大家推荐一本蛇尾书,大模型时代的启动手册!
多模态Chat来了,Salesforce Research学者提出BLIP-2,利用多模态预训练和语言大模型能力在相关任务上取得SOTA,也可以实现多模态对话!