V
主页
85、Differential Transformer 论文原理逐段讲解
发布人
大家好,本期视频带来 Differential Transformer(差分注意力)的论文原理与伪代码讲解,这是近期刚出炉的一篇比较不错的论文,从 LLM 多个任务并验证了差分注意力即使在 scaling 的有效性。希望本期视频对于大家有所帮助。
打开封面
下载高清视频
观看高清视频
视频下载器
Transformer论文逐段精读【论文精读】
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
54、Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读
KAN+Transformer,实验指标获得巨大提升!结合论文与项目详细讲解如何进行融合
68、VQVAE预训练模型的论文原理及PyTorch代码逐行讲解
【深度学习基本功!启动!】带你手敲Transformer代码之-Embedding篇!-神经网络/pytorch深度学习
【带读AI经典论文|100篇】世界顶级大佬带你逐句阅读最重要的100篇AI论文
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
【官方双语】Transformer模型最通俗易懂的讲解,零基础也能听懂!
73、爆火必看的nano-GPT2 Pytorch经典代码逐行讲解
34、Swin Transformer论文精讲及其PyTorch逐行复现
71、VQGAN模型+VQ离散化模块的代码讲解
4、PyTorch的Dataset与DataLoader详细使用教程
63、必看!概率扩散模型(DDPM)与分数扩散模型(SMLD)的联系与区别
28、Vision Transformer(ViT)模型原理及PyTorch逐行实现
transformers一个非常严重的bug——在使用梯度累计的时候 loss不等效
72、爆火的GPT-2论文讲解
1、PyTorch介绍与张量的创建
【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】
(CVPR 2024)即插即用多尺度注意力机制MAB模块,即用即涨点起飞
【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章
59、基于CLIP/ViT模型搭建相似图像检索系统
18、深入剖析PyTorch中的Transformer API源码
64、扩散模型加速采样算法DDIM论文精讲与PyTorch源码逐行解读
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
【研2基本功 Score-based Diffusion 1】手搓Diffusion SDE,数学is all you need
75、Llama源码讲解之RoPE旋转位置编码
边睡边学算法丨第一期
李开复透露「GPT5训练遇到困难,O1模型被迫放出来」OpenAI还有很多私货没有发布
【研2基本功 Score-based Diffusion 2】手搓Diffusion SDE,CCF-A向你招手
第六课 马尔可夫链蒙特卡洛方法
清华微软联手打造Differential Transformer!差分Transformer竟能消除注意力噪声,犹如降噪耳机,精度飙升30%
69、VQGAN+Transformer自回归建模图像生成的论文原理细致讲解
79、Llama源码讲解之自回归采样生成算法
21、Transformer Masked loss原理精讲及其PyTorch逐行实现
81、LLaMA-1 论文导读
2、PyTorch张量的运算API(上)
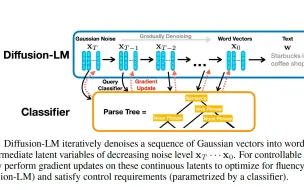
67、DiffusionLM 基于扩散模型的语言模型论文原理精讲
什么是层归一化LayerNorm,为什么Transformer使用层归一化