V
主页
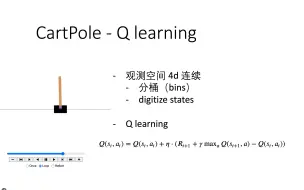
[pytorch 强化学习] 07 迷宫环境(maze environment)Q Learning(value iteration)求解(策略关闭 off)
发布人
code:https://github.com/chunhuizhang/bilibili_vlogs/blob/master/rl/tutorials/06_value_iteration_q_learning.ipynb 迷宫环境:https://www.bilibili.com/video/BV1Ye411P7Sw/?spm_id_from=333.999.0.0 系列视频:https://space.bilibili.com/59807853/channel/collectiondetail?sid=908186
打开封面
下载高清视频
观看高清视频
视频下载器
[pytorch 强化学习] 03 动手写迷宫环境(maze env)状态及动作策略初步(及动画保存)
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[pytorch 强化学习] 02 将 env rendering 保存为 mp4/gif(以 CartPole 为例,mode='rgb_array')
[pytorch 强化学习] 09 (逐行写代码)CartPole Q learning 基于连续状态离散化(digitize 分桶)
[pytorch 强化学习] 05 迷宫环境(maze environment)策略梯度(Policy Gradient)求解
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
[pytorch 强化学习] 11 逐行写代码实现 DQN(ReplayMemory,Transition,DQN as Q function)
[强化学习基础 02] MDP价值迭代算法(value iteration,V(s), Q(s,a), pi(s))
[强化学习基础 01] MDP 基础(概率转移,与POMDP、I-POMDP)
[pytorch 强化学习] 08 CartPole Q learning 连续状态离散化(digitize 分桶)及 display_frame_as_gif
[pytorch 强化学习] 06 迷宫环境(maze environment)SARSA(Q-table,value iteration)求解
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
强推!2024年最适合初学者入门学习的《机器学习+深度学习+强化学习》上海交大和腾讯强强联合打造!太全面了!
[pytorch 强化学习] 04 迷宫环境(maze environment)封装 MazeEnv、Agent 类
强化学习,启动!
强化学习魅力时刻
太完整了!我居然3天时间就掌握了【机器学习+深度学习+强化学习+PyTorch】理论到实战,多亏了这个课程,绝对通俗易懂纯干货分享!
强推!我竟然半天就学会了【强化学习】!(PPO、Q-learning、DQN、A3C)算法原理及实战教你用A3C玩转超级马里奥!(深度强化学习/强化学习入门)
[pytorch 强化学习] 13 基于 pytorch 神经网络实现 policy gradient(REINFORCE)求解 CartPole
强化小伙终于起立了
不愧是顶会收割机!迪哥精讲强化学习4大主流算法:PPO、Q-learning、DQN、A3C 50集入门到精通!
【Python】人形机器人——强化学习
RLHF基于人类反馈的强化学习动画讲解(LLM)
这应该是你能找到的讲解最系统全面的【强化学习】教程!北大出身王树森教授从零到一保姆式教学,小白也能很好懂!
斯坦福大学《强化学习|Stanford CS234 Reinforcement Learning 2024》deepseek翻译
CV强化论文分享20241018-1
通俗理解大模型从预训练到微调实战!P-Tuning微调、Lora-QLora、RLHF基于人类反馈的强化学习
【简短】一分钟Office激活, 一行代码丨适合女生男生,2024,2025,带刀切图office,office,github,word,excel,ppt
210:cyber 无人船优化反步控制 轨迹跟踪 强化学习Actor-critic架构,李雅普诺夫稳定性,优化反布控制,强化学习(RL),水面舰艇
Decaying Action Priors for Accelerated Imitation Learning of Torque-Based Legged
Lec9: 强化学习的概率论基础Review(世界是确定的,条件概率,条件期望,towering property)
【2024汽车年会】大数据和人工智能:从系统辨识到AI建模 从最优控制到强化学习
手撕 AlphaGo Zero
6个智能体的编队导航与避障_补充实验
Diffusion Policy 结合 PPO 模仿+强化 (下)
Stanford CS234 2024 Spring | 强化学习 | Reinforcement Learning
[pytorch 强化学习] 12 逐行写代码实现 DQN 完全体
[pytorch optim] pytorch 作为一个通用优化问题求解器(目标函数、决策变量)
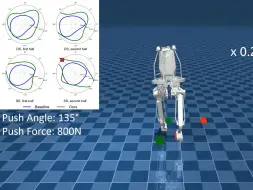
[搬] 稳健的类人机器人行走-通过强化学习增强基于模型的控制
CV强化论文分享20241018-2