V
主页
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
发布人
DressCode: Autoregressively Sewing and Generating Garments from Text Guidance Kai He, Kaixin Yao, Qixuan Zhang, Lingjie Liu, Jingyi Yu, Lan Xu 项目主页:https://ihe-kaii.github.io/DressCode/ Apparel's significant role in human appearance underscores the importance of garment digitalization for digital human creation. Recent advances in 3D content creation are pivotal for digital human creation. Nonetheless, garment generation from text guidance is still nascent. We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-on, and digital human creation. We first introduce SewingGPT, a GPT-based architecture integrating cross-attention with text-conditioned embedding to generate sewing patterns with text guidance. We then tailor a pre-trained Stable Diffusion to generate tile-based Physically-based Rendering (PBR) textures for the garments. By leveraging a large language model, our framework generates CG-friendly garments through natural language interaction. It also facilitates pattern completion and texture editing, streamlining the design process through user-friendly interaction. This framework fosters innovation by allowing creators to freely experiment with designs and incorporate unique elements into their work. With comprehensive evaluations and comparisons with other state-of-the-art methods, our method showcases superior quality and alignment with input prompts. User studies further validate our high-quality rendering results, highlighting its practical utility and potential in production settings.
打开封面
下载高清视频
观看高清视频
视频下载器
[群友工作] 上科大,Deemos等推出Media2Face,语音合成 3D 面部动画的新算法以及多型、多样化的扫描级别语音与3D协同数据集M2M-D
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF进展] Oppo, Buffalo, 上科大提出NeuRBF,使用自适应的RBF进行神经场表达,相比INGP, TensoRF等取得更好的渲染效果
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[Diffusion生成NeRF] TUM, Apple提出HyperDiffusion,用Diffusion计算神经场权重,统一框架下生成3D权重或4D动画
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
[NeRF进展,时间一致动态场景重建] MPI, Meta提出SceNeRFlow,一种通用的,非刚性场景的,时间一致性的NeRF重建方法,可重建大尺度运动
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[AIGC视频生生]Google等提出Lumiere,使用时空U-Net,单次传递,一次性生成视频完整时间,实现高质量文本转视频、图像转视频、视频修复、风格化等
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[NeRF编辑] 腾讯Pixel Lab,上科大提出Neural Imposters,一种将四面体网格与隐式表达混合的方法,可以实现神经场的编辑和控制操作
[动态3DGS与场景编辑] 请香港大学黄熠华博士一起讲讲SC-GS和Deformable 3DGS两项工作
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
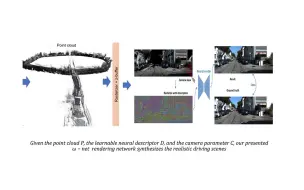
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[3DGS编辑] 南洋理工、清华、商汤提出GaussianEditor,可交互式编辑3DGS场景,并提供WebUI实时体验
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF App] Luma AI推出新APP:Flythroughs,unbounded场景通过iPhone即可完成建模和漫游,已经发布上线,可开放体验
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,动态NeRF编码与串流] 上海科技大学、NeuDim推出ReRF,通过设计辐射场编码Codec,实现FVV长内容低码率编码与实时传输与播控
[NeRF进展,Relighting方向] 浙江大学,MSRA等提出一种新的可重光照的NeRF的表达,通过向MLP提供多种hint,实现不同光照效果
VLOG 生活篇|在上科大的小时光
[AIGC进展,文本到3D Mesh] nVidia在CVPR 23年的Highlight工作Magic3D,选择使用Mesh进行扩散,生成高清晰度Mesh
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[单视图重建]ETH、Google和TUM提出KYN,一种基于NeRF的3D密度重建方法,使用单视图恢复3D形状,提升了零样本泛化能力
[NeRF进展] 多伦多大学,SFU,Google和Adobe提出Bayers' Rays,在预训练的NeRF里预测不确定性,清除由不完整或遮挡造成的重建缺陷
[NeRF进展] 图宾根大学、Google提出Binary Opacity Grids,加强版本BakedSDF,生成视图质量更高,移动设备场景实时渲染
[AIGC进展,文本生成室内3D Mesh] 慕尼黑工业大学Matthias团队与密西根大学Justin团队,推出Text2Room,用文本生成室内3D场景建模
[动态NeRF进展] ETH,微软,苏黎世大学提出ResFields,将复杂的时域层合并至神经场,解决MLP时域复杂信号表达力弱问题,合用于动态形状建模问题
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果