V
主页
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
发布人
本期 code:https://github.com/chunhuizhang/pytorch_distribute_tutorials/blob/main/tutorials/deepspeed_accelerate/megtron_lm.ipynb 分块矩阵与张量并行:BV1Jy4y1A76p llama3 embedding:BV18E421A7TQ
打开封面
下载高清视频
观看高清视频
视频下载器
[pytorch distributed] accelerate 基本用法(config,launch)数据并行
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
[pytorch distributed] 01 nn.DataParallel 数据并行初步
[pytorch distributed] 从 DDP、模型并行、流水线并行到 FSDP(NCCL,deepspeed 与 Accelerate)
[pytorch distributed] 04 模型并行(model parallel)on ResNet50
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
[pytorch distributed] deepspeed 基本概念、原理(os+g+p)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[pytorch distributed] 03 DDP 初步应用(Trainer,torchrun)
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[pytorch distributed] amp 原理,automatic mixed precision 自动混合精度
[pytorch optim] Adam 与 AdamW,L2 reg 与 weight decay,deepseed
[pytorch] nn.Embedding 前向查表索引过程与 one hot 关系及 max_norm 的作用
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
[动手写神经网络] pytorch 高维张量 Tensor 维度操作与处理,einops
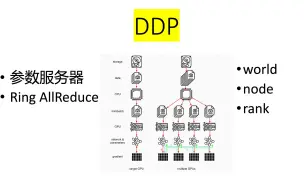
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
[LLMs inference] quantization 量化整体介绍(bitsandbytes、GPTQ、GGUF、AWQ)
[动手写神经网络] 手动实现 Transformer Encoder
[pytorch 加速] CPU传输 & GPU计算的并行(pin_memory,non_blocking)
[pytorch 强化学习] 02 将 env rendering 保存为 mp4/gif(以 CartPole 为例,mode='rgb_array')
[pytorch distributed] nccl 集合通信(collective communication)
[pytorch] [求导练习] 03 计算图(computation graph)及链式法则(chain rule)反向传播过程
[调包侠] 使用 PyTorch Swin Transformer 完成图像分类
[pytorch] Tensor 轴(axis)交换,transpose(转置)、swapaxes、permute
[pytorch] torch.einsum 到索引到矩阵运算(index、shape、dimension、axis)
[LLMs tuning] 02 accelerate ddp 与 trl SFTTrainer
[pytorch 强化学习] 11 逐行写代码实现 DQN(ReplayMemory,Transition,DQN as Q function)
[GPT 番外] tied/share tensors wte与lm_head(GPT2LMHeadModel)
[LLM 番外] 自回归语言模型cross entropy loss,及 PPL 评估
[LangChain] 03 LangGraph 基本概念(AgentState、StateGraph,nodes,edges)
[pytorch] [求导练习] 06 计算图(computation graph)细节之 retain graph(multi output/backwar)
[pytorch] 多项式分布及采样(torch.multinomial, torch distribution Categorical)
[pytorch 网络拓扑结构] 深入理解 nn.LayerNorm 的计算过程
[AI 核心概念及计算] 概率计算 01 pytorch 最大似然估计(MLE)伯努利分布的参数
[pytorch] 深入理解 nn.KLDivLoss(kl 散度) 与 nn.CrossEntropyLoss(交叉熵)
[pytorch] [求导练习] 04 前向计算与反向传播与梯度更新(forward,loss.backward(), optimizer.step)
[pytorch] BN、LN、RMSNorm 及 pre LN vs. post LN 对比,标准化
[pytorch 强化学习] 08 CartPole Q learning 连续状态离散化(digitize 分桶)及 display_frame_as_gif
[pytorch 模型拓扑结构] 深入理解 nn.BCELoss 计算过程及 backward 及其与 CrossEntropyLoss 的区别与联系