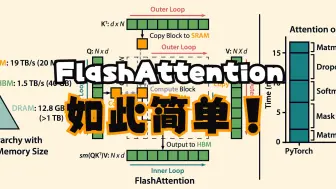
V
主页
flash attention的cuda编程
发布人
简单的flash attention介绍,以及flash attention算法流程的介绍,包括flash attention的CUDA代码以及matmul的CUDA代码优化技巧
打开封面
下载高清视频
观看高清视频
视频下载器
[手写flash attention v1 & v2] baseline的基础实现
CUDA编程基础入门系列(持续更新)
并行计算(CUDA编程)
Flash Attention 为什么那么快?原理讲解
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
CUDA Python--系列课程(主讲:何琨)
论文分享:新型注意力算法FlashAttention
001从最简单的cuda程序开始
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
论文分享:从Online Softmax到FlashAttention-2
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
FlashAttention: 更快训练更长上下文的GPT【论文粗读·6】
cuda(cutlass)编程之swizzle
【CUDA Mode 2024】中英字幕
神经网络-量化与部署,进阶之路迟早要越过的大山
Lecture 12: Flash Attention
大模型量化一网打尽(一)理论基础
高性能计算 2023 @High Performance Computing Course | 附字幕版
Flash Attention!
tensor core实现矩阵乘法
⏱️78s看懂FlashAttention【有点意思·1】
GPU并行计算与CUDA编程
【并行计算】CUDA在现代C++中如何运用?看这一个就够了!
CUDA 编程入门
CUDA编程的基本知识以及CUDA实现add运算编程讲解
llama.cpp 源码解析-- CUDA版本流程与逐算子详解
Flash Attention原理!数据布局转换与内存优化!【推理引擎】离线优化第04篇
经典 CUDA C/C++人工智能教程(AI&机器学习&HPC&科学仿真)
cuda实现matmul的重新解读
【GPU 计算 CMPS224 2021】贝鲁特美国大学—中英字幕
大模型LLM入门书籍:豆瓣9.9分外网超火的大模型黑书<基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理>附PDF
cuda实现规约算法和softmax开发
看了这个视频你才能真正搞懂FlashAttention, S4和Mamba
北大未名超算队 高性能计算入门讲座(一):概论
NVIDIA CUDA初级教程视频
【大模型量化】llama.cpp轻量化模型部署及量化
CUDA MODE Lecture 12: Flash Attention
初学CUDA编程讲的最清楚的一个视频
HPC基本知识和计算机体系架构介绍
详解TensorRT的C++/Python高性能部署,实战应用到项目