V
主页
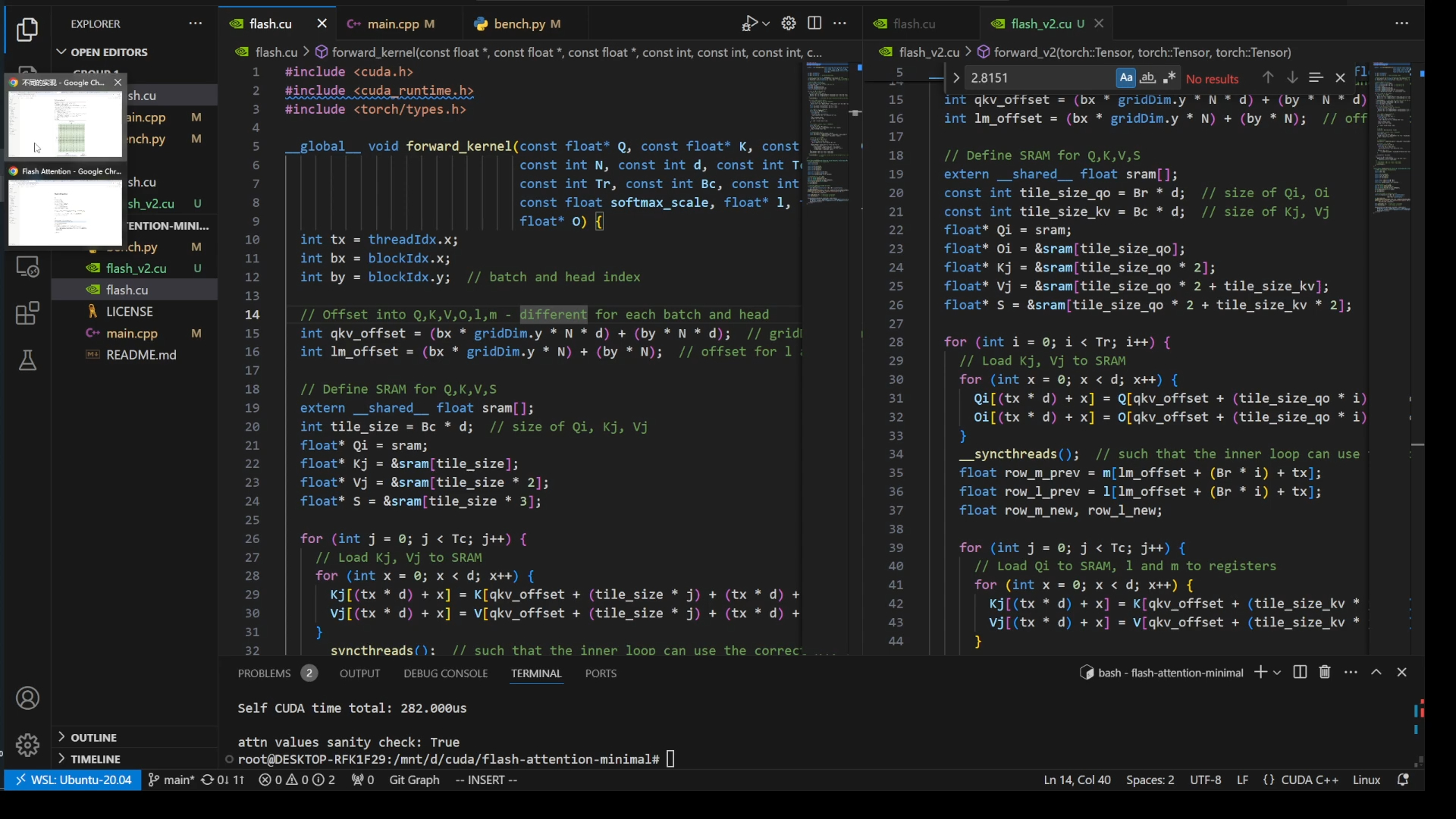
[手写flash attention v1 & v2] baseline的基础实现
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
Flash Attention 为什么那么快?原理讲解
flash attention的cuda编程
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
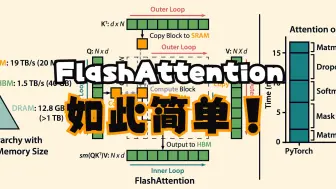
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
Flash Attention原理!数据布局转换与内存优化!【推理引擎】离线优化第04篇
⏱️78s看懂FlashAttention【有点意思·1】
【研1基本功 (真的很简单)LoRA 低秩微调】大模型微调基本方法1 —— bonus "Focal loss"
姚顺雨-语言智能体博士答辩 Language Agents: From Next-Token Prediction to Digital Automation
Flash attention论文解读
手写大模型代码(上)( LLM:从零到一)【6】
全网首篇探究GPU内CUDAcore和TensorCore并行计算
论文分享:从Online Softmax到FlashAttention-2
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
[c++进阶] 实现图中的-->重载操作
cuda实现规约算法和softmax开发
[手写gemm] tensor_core & cuda_core fusion gemm的尝试
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
Lecture 12: Flash Attention
FlashAttention: 更快训练更长上下文的GPT【论文粗读·6】
Triton入门系列-Vector Add
Qwen2为何“高分低能”?实测中表现还不如Qwen1.5!
Triton入门系列-l2 cache optim
cuda编程从入门到入土 p1 - hello-gpu
零基础学习强化学习算法:ppo
nlp开发利器——vscode debug nlp大工程(最最最优雅的方式)
【论文精读】为什么用SDE(随机微分方程)来描述扩散过程 (3.1节,3.2节)
CUDA MODE Lecture 12: Flash Attention
flashattention原理深入分析
cuda(cutlass)编程之swizzle
一个视频让你对flash attention2下头(比较FA2和sdpa的效率)
神经网络-量化与部署,进阶之路迟早要越过的大山
多模态大模型LLaVA模型讲解——transformers源码解读
使用c++编写操作系统
MLIR入门-构建编译环境
Ray入门指北-Tasks
一个视频看懂如何从SDE视角看生成模型
揭秘变分自编码器(VAE)背后的数学原理+代码实现
[cutlass 3.0] cute swizzle中的一些细节
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention