V
主页
[数据集] 上海AI实验室、商汤等提出DNA-Rendering,一个多样化的,高精度,以人物为中心的,包含2D/3D人体关键点,前景mask等大规模人体数据集
发布人
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering Authors: Wei Cheng, Ruixiang Chen, Wanqi Yin, Siming Fan, Keyu Chen, Honglin He, Huiwen Luo, Zhongang Cai, Jingbo Wang, Yang Gao, Zhengming Yu, Zhengyu Lin, Daxuan Ren, Lei Yang, Ziwei Liu, Chen Change Loy, Chen Qian, Wayne Wu, Dahua Lin, Bo Dai, Kwan-Yee Lin 上海AI实验室,商汤Research,S-LAB, NTU, 香港中文大学 项目主页:https://dna-rendering.github.io/ Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this 。。。
打开封面
下载高清视频
观看高清视频
视频下载器
[3D生成] 南洋理工、香港中文、上海AI实验室提出DiffTF,一个基于扩散模型和三平面的前馈框架,用于生成多样化的、大语料量规模的真实世界3D物体
在新加坡进国大南大有多容易?
[Generative AI,自然场景生成] 山东大学、腾讯、北大提出Sin3DGen,一个3D生成模型,使用单个patch生成3D场景
[群友工作] 上科大,Deemos等推出Media2Face,语音合成 3D 面部动画的新算法以及多型、多样化的扫描级别语音与3D协同数据集M2M-D
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[Neural Rendering火热应用] 日本东京公司产品xpression camera使用神经网络渲染+人脸关键点检测与跟踪实现高清换脸虚拟摄像头
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
I3D 2023 Papers Session 1 - Neural Rendering and Image Warping
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
[3DGS编辑] 南洋理工、清华、商汤提出GaussianEditor,可交互式编辑3DGS场景,并提供WebUI实时体验
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[CVPR大佬讲paper第二期] 上海AI实验室鲁涛大佬讲Scaffold-GS, GSDF, OctreeGS录制内容
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展,开源大规模场景] DNMP(同济、港中文、上海AI实验室,CPII),一种使用可变形神经mesh的,高质量快速的重建和渲染城市级别神经场的方法
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[人体3D动画] 清华、哈工大、MPI提出ProxyCap,首个使用2D骨架序列和3D旋转运动数据集,使用单目采集视频实时进行3D人体动作采集
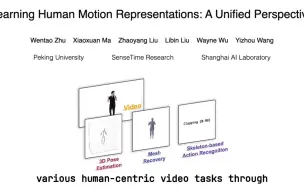
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[Neural Rendering,任意拓扑重建] 香港大学、腾讯游戏、普朗克研究院等提出NeuralUDF,用来重建衣物等任意拓扑曲面的方法,弥补SDF不足
TUM AI Lecture Series - Ben Poole(Google Brain)基于2D先验的3D生成方法(2023.07.18)
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,编辑方向] 三星多伦多AI中心,多伦多大学,约克大学等:SPIn-NeRF,可快快速完成3D Segmentation和Inpainting任务
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
[点云法向,SIGGRAPH最佳论文] 山东大学、香港大学等提出通过正则化Winding-number场,全局一致性点云法向算法
[三维重建] nVidia提出NKSR,一种新的从噪声的稀疏的点云重建地球级别3D表面的方法,可以在数秒中内完成对百万点的重建,并达到极好的效果
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
25年QS世界大学排名前50大学分析
[Diffusion+Transformer,人体动画进展] 阿里达摩院刚刚提出一个统一的预训练扩散模型MoFusion,用于人体动画合成 (arXiv)
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频