V
主页
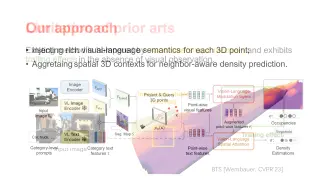
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
发布人
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models Jiale Xu(ARC Lab,上海科技大学),Xintao Wang,Weihao Cheng,Yan-Pei Cao,Ying Shan(ARC Lab),Xiaohu Qie(腾讯PCG),Shenghua Gao(上海科技大学,上海工程技术研究中心) 项目主页:https://bluestyle97.github.io/dream3d/ 近期CLIP引导的3D优化方法,如DreamFields和PureCLIPNeRF,在zero-shot的文本生成3D上取得了非常好的合成效果。但是由于从头训练和没有任何先验知识的随机初始化,这些方法通常不能生成准确和可信可符合文本描述的3D结构数据。在这个工作里,我们首次尝试引入一个显式3D先验形状,来优化CLIP引导的3D优化任务。具体的讲,我们首先在文本到形状转换时,使用输入文本生成了一个质量的3D形状来作为先验知识。然后我们使用它来初始化神经辐射场,并使用完整prompt进行优化。对文本到形状的合成,我们提出了一个简单但有效的方法,使用一个强力的文本转图片的扩散模型,直接将文本和图片进行链接。为了让文本到图片转化生成的图片,与图片到形状生成的形状之间的差距变小,我们进一步提出把可学习的文本输入和把为了渲染图片生成的文本到图片扩散模型精调过程进行联合优化。我们的方法,Dream3D,相比目前SOTA方法,可以生成非常有创意的3D内容,并具有更好的视觉效果以及更准确的形状。 Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual...
打开封面
下载高清视频
观看高清视频
视频下载器
可灵kling vs Sora效果对比!强啊,真的的强!
[单视图重建]ETH、Google和TUM提出KYN,一种基于NeRF的3D密度重建方法,使用单视图恢复3D形状,提升了零样本泛化能力
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
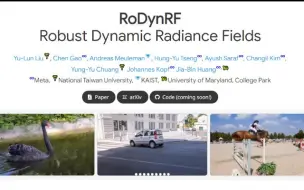
[NeRF进展,鲁棒的动态NeRF]Meta,台湾大学、KAIST、马里兰大学提出RoDynRF,联合预测静态、动态和相机姿态焦点信息提升鲁棒性
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,动态3D场景表达]UC伯克利、意大利技术研究院、丹麦技术大学提出KPlane,使用6-plane特征表现4D体数据,HexPlane类似解决方案
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
执牛耳者 | 沈定刚教授:探索医疗人工智能
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力
[3D生成] 港科大、LightIllusions等提出CraftsMan(匠心),使用3D原生diffusion生成高质量3D网格,也可支持可交互的网格生成
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[AIGC视频生生]Google等提出Lumiere,使用时空U-Net,单次传递,一次性生成视频完整时间,实现高质量文本转视频、图像转视频、视频修复、风格化等
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
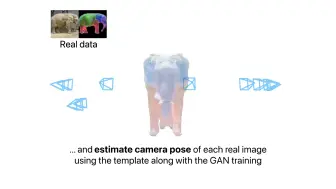
[3DGAN]浙江大学、香港理工和蚂蚁提出TeFF,无相机位姿3D感知GAN训练方法,在多个挑战的2D数据集上训练,生成样本可360度图像合成,并有完整几何形状
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
[NeRF,超高清渲染方向]阿里提出4K级别的超高清NeRF训练和渲染方法,在主观和客观质量评价下都取得了很好的效果
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF编辑] 腾讯Pixel Lab,上科大提出Neural Imposters,一种将四面体网格与隐式表达混合的方法,可以实现神经场的编辑和控制操作
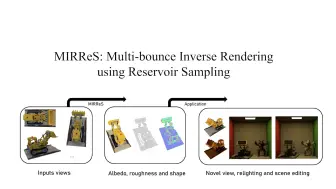
[逆渲染] 南洋理工、浙大、商汤等提出MIRReS,一种NeRF逆渲染算法,加入多次反弹光追,在复杂场景下达到更好的几何、材质和光照的重建效果
[NeRF进展,自动数据收集] INSA, UCBL, Meta提出AutoNeRF,一种不需要人工干预的自动agent,采集NeRF训练数据,协助完成下游任务
[NeRF+自动驾驶] 浙大、图宾根大学提出PanopticNeRF360,将3D标记与带噪声的2D语义线索组合生成一致性全景标签和高质量任意视角图片的方法
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[3DGS] 南开大学实时新视图合成、HDR 渲染、重新聚焦和色调映射更改,相比体渲染,训练速度缩短至1%,2K分辨率渲染提升4000倍