V
主页
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
发布人
PAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System Identification Xuan Li(UCLA) , Yi-Ling Qiao(马里兰大学) , Peter Yichen Chen(MIT CSAIL, 哥伦比亚大学), Krishna Murthy Jatavallabhula(MIT CSAIL) , Ming Lin(马里兰大学) , Chenfanfu Jiang(UCLA) , Chuang Gan(马萨诸塞大学阿默斯特分校,IBM Watson AI Lab) 项目主页:https://sites.google.com/view/PAC-NeRF Github主页:https://github.com/xuan-li/PAC-NeRF Existing approaches to system identification (estimating the physical parameters of an object) from videos assume known object geometries. This precludes their applicability in a vast majority of scenes where object geometries are complex or unknown. In this work, we aim to identify parameters characterizing a physical system from a set of multi-view videos without any assumption on object geometry or topology. To this end, we propose “Physics Augmented Continuum Neural Radiance Fields” (PAC-NeRF), to estimate both the unknown geometry and physical parameters of highly dynamic objects from multi-view videos. We design PAC-NeRF to only ever produce physically plausible states by enforcing the neural radiance field to follow the conservation laws of continuum mechanics. For this, we design a hybrid Eulerian-Lagrangian representation of the neural radiance field, i.e., we use the Eulerian grid representation for NeRF density and color fields, while advecting the neural radiance fields via Lagrangian particles. This hybrid Eulerian-Lagrangian representation seamlessly blends efficient neural rendering with the material point method (MPM) for robust differentiable physics simulation. We validate the effectiveness of our proposed framework on geometry and physical parameter estimation over a vast range of materials, including elastic bodies, plasticine, sand, Newtonian and non-Newtonian fluids, and demonstrate significant performance gain on most tasks.
打开封面
下载高清视频
观看高清视频
视频下载器
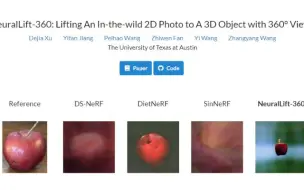
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[神经渲染进展,人体与物体合成] 首尔大学、Meta提出NCHO,一种将人体与物体组合,且反应物理接触关系变化的无监督学习模型,支持重新组合与动画效果
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,无pose prior的NeRF重建] 牛津大学提出NoPe-NeRF,在没有先验相机pose信息的情况下,优化NeRF和相机姿态(CVPR)
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,动态NeRF编码与串流] 上海科技大学、NeuDim推出ReRF,通过设计辐射场编码Codec,实现FVV长内容低码率编码与实时传输与播控
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
UCLA博士答辩 | 阿芬波、湍流及太阳风结构:来自帕克太阳探针号的启示
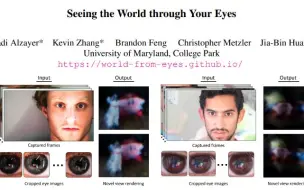
[NeRF进展,反射场景提取] 马里兰大学的新脑洞,通过眼睛反射重建所看到的场景,又一个使用神经场通过反射完成场景重建
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[NeRF进展,严重相机pose错位重建,强于BARF] 西安交通大学、蚂蚁金服、腾讯AI Lab提出L2G-NeRF,使用局部-全局优化相机严重错位重建问题
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
IBM客户关系管理系统 颜冠英 | 2002年广告
[NeRF进展,实时流建模] 斯坦福大学提出NeRFBridge,将机器人操作系统ROS与nerfstudio桥接,实时在线流式训练NeRF模型
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)