V
主页
[A100 02] GPU 服务器压力测试,gpu burn,cpu burn,cuda samples
发布人
本期 code:https://github.com/chunhuizhang/deeplearning-envs/blob/main/A100/gpuburn_cpuburn_cuda_samples.ipynb A100 开箱:BV1Yt42187NM 双4090:BV1A54y1F7kN
打开封面
下载高清视频
观看高清视频
视频下载器
[装机指南] 02 双卡4090 gpu-burn,cpu-burn,cuda-samples 性能测试
[A100 01] A100 服务器开箱,超微平台,gpu、cpu、内存、硬盘等信息查看
【深度学习环境搭建】01 本机、GPU服务器端深度学习环境搭建(代码、数据共享)
【深度学习环境搭建】02 gpu 服务器端部署 jupyter notebook server
[小白向-深度学习装机指南] 01 双4090 涡轮版开箱启动 vlog(gpu burn,cpu burn)
[全栈深度学习] 01 docker 工具的基本使用及 nvidia cuda pytorch 镜像
[显卡环境] CUDA_VISIBLE_DEVICES 控制显卡可见性
[全栈深度学习] 02 vscode remote(远程)gpus 服务器开发调试 debugger(以 nanoGPT 为例)
[AI硬件科普] 内存/显存带宽,从 NVIDIA 到苹果 M4
[personal chatgpt] 从 RoPE 到 CoPE(绝对位置编码,相对位置编码,Contextual Position Encoding)
[einops 01] einsum 补充与 einops 初步(实现 ViT 的图像分块)
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
[蒙特卡洛方法] 02 重要性采样(importance sampling)及 python 实现
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[pytorch distributed] 01 nn.DataParallel 数据并行初步
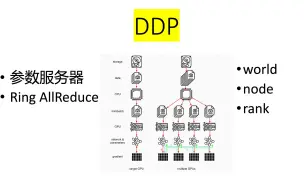
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[工具的使用] python jupyter 环境安装配置拓展(nbextension)(ExcecuteTime:执行时间,Table of Content)
[sbert 01] sentence-transformers pipeline
[动手写神经网络] 手动实现 Transformer Encoder
[python 多进程、多线程、协程] 02 用 python 多线程实现生产者消费者流程
[pytorch] [求导练习] 02 softmax 函数自动求导练习(autograd,Jacobian matrix)
【python 运筹优化】scipy.optimize.minimize 使用
[蒙特卡洛方法] 04 重要性采样补充,数学性质及 On-policy vs. Off-policy
[LLMs 实践] 04 PEFT/LoRA 源码分析
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[LLM & AIGC] nvidia chat with rtx 初体验
[AI 核心概念及计算] 优化 01 梯度下降(gradient descent)与梯度上升(gradient ascent)细节及可视化分析
[LangChain] 03 LangGraph 基本概念(AgentState、StateGraph,nodes,edges)
[pytorch 网络拓扑结构] 深入理解 nn.LayerNorm 的计算过程
[pytorch 强化学习] 02 将 env rendering 保存为 mp4/gif(以 CartPole 为例,mode='rgb_array')
[diffusion] 生成模型基础 VAE 原理及实现
[矩阵分析] LoRA 矩阵分析基础之 SVD low rank approximation(低秩逼近)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[pytorch] [求导练习] 03 计算图(computation graph)及链式法则(chain rule)反向传播过程
[Python 机器学习] 深入理解 numpy(ndarray)的 axis(轴/维度)
[LLM+RL] 合成数据与model collapse,nature 正刊封面
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
[全栈算法] docker nvidia pytorch gpu 环境及容器操作,端口号映射
[LLMs 实践] 221 llama2 源码分析 generate 的完整过程
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程