V
主页
[sbert 01] sentence-transformers pipeline
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/sbert-tutorials/sentence-transformers-pipeline.ipynb hinge-loss:BV1ai4y1x7LN
打开封面
下载高清视频
观看高清视频
视频下载器
[sbert 02] sbert 前向及损失函数pooling method计算细节
[personal chatgpt] peft LoRA merge pipeline(lora inject,svd)
[A100 01] A100 服务器开箱,超微平台,gpu、cpu、内存、硬盘等信息查看
[A100 02] GPU 服务器压力测试,gpu burn,cpu burn,cuda samples
[LLMs tuning] 05 StackLlama、SFT+DPO(代码组织、数据处理,pipeline)
[LLMs inference] hf transformers 中的 KV cache
[强化学习基础 01] MDP 基础(概率转移,与POMDP、I-POMDP)
[einops 01] einsum 补充与 einops 初步(实现 ViT 的图像分块)
[动手写神经网络] 手动实现 Transformer Encoder
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)
[蒙特卡洛方法] 04 重要性采样补充,数学性质及 On-policy vs. Off-policy
[personal chatgpt] instructGPT 中的 reward modeling,概率建模与损失函数性质
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
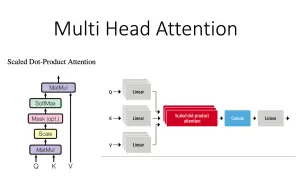
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[pytorch distributed] deepspeed 基本概念、原理(os+g+p)
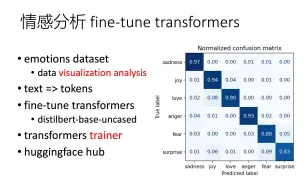
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[动手写 Transformer] 从 RNN 到 Transformer,为什么需要位置编码(position encoding)
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
一次学懂对比学习:MOCO
【搜索算法】【search】01 python-astar 图上搜索(graph search)f(n)=g(n)+h(n)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[personal chatgpt] trl 基础介绍:reward model,ppotrainer
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
[diffusion] 生成模型基础 VAE 原理及实现
动画解释深度学习:使用 SimCLR 进行对比学习
[AI Agent] Agentic Reasoning & workflow工作流,及translation-agent 一个具体的 agent 项目
[mcts] 02 mcts from scartch(UCTNode,uct_search, pUCT,树的可视化)
【爬虫】【豆瓣爬虫】01 豆瓣热门电影/电视,基于 api 爬虫
[LLMs 实践] 221 llama2 源码分析 generate 的完整过程
[LLMs 实践] 09 BPE gpt2 tokenizer 与 train tokenizer
[LangChain] 03 LangGraph 基本概念(AgentState、StateGraph,nodes,edges)
[动手写神经网络] pytorch 高维张量 Tensor 维度操作与处理,einops
【python 运筹优化】scipy.optimize.minimize 使用
[LLMs 实践] 19 llama2 源码分析 RoPE apply_rotary_emb 从绝对位置编码到相对位置编码
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[pytorch 模型拓扑结构] 深入理解 nn.BCELoss 计算过程及 backward 及其与 CrossEntropyLoss 的区别与联系