V
主页
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
发布人
NeRF-Art: Text-Driven Neural Radiance Fields Stylization Can Wang(香港城市大学), Ruixiang Jiang(香港理工大学), Menglei Chai(Snapchat Creative Vision), Mingming He(南加州创意技术研究所), Dongdong Chen(微软Cloud AI), Jing Liao(香港城市大学) 项目主页:https://cassiepython.github.io/nerfart/ Github项目主页:https://github.com/cassiePython/NeRF-Art 作为三维场景的强有力的表示方式,NeRF可以通过多角度图片合成高质量视角内容。然而风格化NeRF,尤其使用文本驱动的对外观和几何同时进行风格化模拟操作,仍然是非常挑战的。在这个工作中,我们提出NeRF-Art,一个文本驱动的NeRF风格化方法,用来将一个预训练的NeRF模型通过文本进行风格化改变。之前的方法缺乏足够的几何变形和纹理细节,或是需要网格来引导风格化过程。与它们不同,我们的方法可以将一个三维的场景通过几何和外观的变化,而不需要任何网格引导,迁移到目标风格特征。 这是通过引入一个全局-局域化对比学习策略,组合了方向约束来同时控制目标风格的轨迹和强度。另外,我们引入了一个权重的规范化方法来有效地抑制云化缺陷和几何噪声,这些都是在调整几何风格的时候密度场变换时很容易引入的。通过大量在不同风格的实验,我们发现我们的方法是有效且鲁棒的,不仅是对单视角合成问题,对多视角一致性问题也是一样。 As a powerful representation of 3D scenes, the neural radiance field (NeRF) enables high-quality novel view synthesis from multi-view images. Stylizing NeRF, however, remains challenging, especially on simulating a text-guided style with both the appearance and the geometry altered simultaneously. In this paper, we present NeRF-Art, a text-guided NeRF stylization approach that manipulates the style of a pre-trained NeRF model with a simple text prompt. Unlike previous approaches that either lack sufficient geometry deformations and texture details or require meshes to guide the stylization, our method can shift a 3D scene to the target style characterized by desired geometry and appearance variations without any mesh guidance. This is achieved by introducing a novel global-local contrastive learning strategy, combined with the directional constraint to simultaneously control both the trajectory and the strength of the target style. Moreover, we adopt a weight regularization method to effectively suppress cloudy artifacts and geometry noises which arise easily when the density field is transformed during geometry stylization.....
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF+文本转3D] nVidia,多伦多大学Sanja团队:ATT3D,在一秒内使用文本生成3D的方法,极大提升了生成速度,并可完成简单的3D转换型动画
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF产品应用] 开源的NerfStudio(目前Github star 2600)使用不同设备采集后重建、渲染效果
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[AIGC进展,使用shape+文本生成纹理] 特拉维夫大学提出TEXTure,通在已知3D shape情况下,使用文本可生成、编辑和迁移纹理效果
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
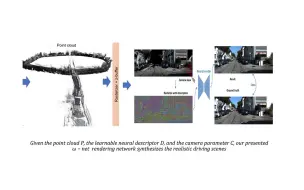
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
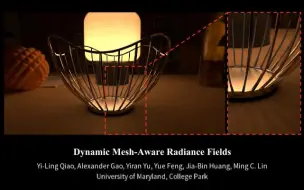
[动态NeRF进展]马里兰大学提出DMRF,一种在渲染和模拟中混合了Mesh和NeRF的方法,提出了光源、阴影和物理模拟的可实时交互方法,在网格插入取得良好效果
[NeRF进展,场景天气风格化渲染]UIUC、浙江大学,马里兰大学提出ClimateNeRF,在NeRF场景中融合天气物理渲染,实现真实感天气场景渲染效果
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展] Strivec(USC, UCSD, Adobe研究院),稀疏分布紧凑分解的局部张量特征grid的辐射场,比TensoRF和NGP效果好参数少
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[NeRF进展,效果提升] TUM与Meta推出GANeRF,使用GAN来解决视角观察缺陷以及小的光照变化带来的重建质量不佳问题,提升1.4dB以上
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[3D生成] 浙大、字节SIG 24工作Coin3D,使用粗糙模型三维控制,可控且交互地生成三维资产,提升导出带纹理网格的质量
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[Avatar生成] 快手、卡迪夫大学提出TRAvatar,高保真度、实时动态全局光照,可变表情的Avatar生成方法
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF,场景语义建模与应用]Meta提出SSDNeRF,首个通用NeRF场景语义分割方法,将场景按语议分割建模,让NeRF二次编辑、丰富动画场景变为可能
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展] MoFaNeRF,基于NeRF的面部可变形模型,让面部拟合、生成、面部绑定、面部编辑更容易,效果更好(ECCV 2022)
[NeRF,超高清渲染方向]阿里提出4K级别的超高清NeRF训练和渲染方法,在主观和客观质量评价下都取得了很好的效果
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
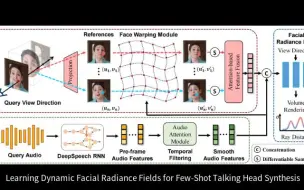
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
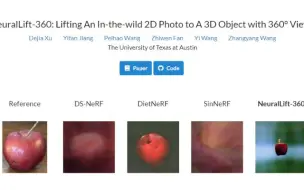
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP