V
主页
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
发布人
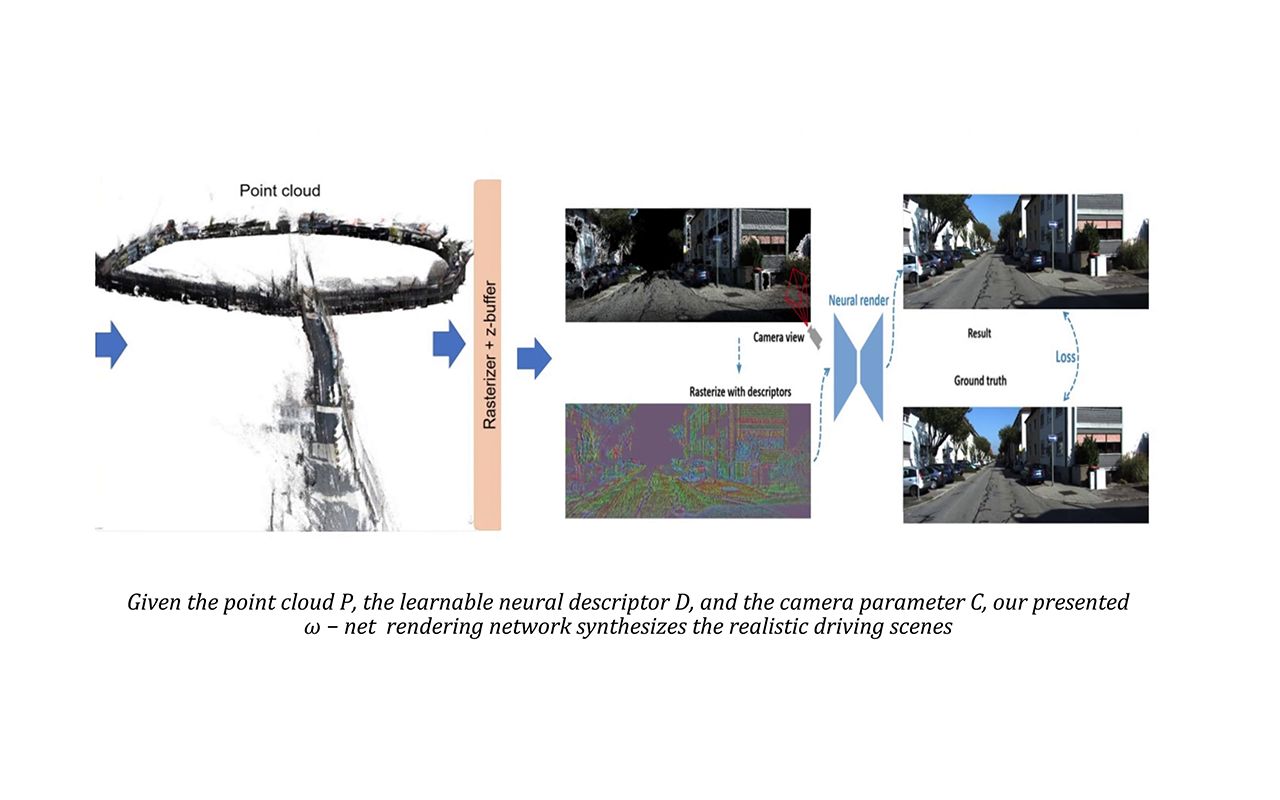
READ: Large-Scale Neural Scene Rendering for Autonomous Driving (AAAI 2023) Zhuopeng Li, Lu Li, Zeyu Ma, Ping Zhang, Junbo Chen, Jianke Zhu(浙江大学) Github地址:https://github.com/JOP-Lee/READ 论文地址:https://arxiv.org/abs/2205.05509 在多媒体领域里,合成自由视角真实感图片是一项非常重要的工作。在辅助驾驶以及它们在自动驾驶里的应用中,在不同场景中的实验变得非常有挑战。尽管照片级别真实感的街景可以使用图像到图像的转换方法生成,但因为它没有3D信息,所以没办法生成相关场景。在这个工作中,我们提出自动驾驶场景方法(READ),一个大尺度神经网络渲染方法,可以通过在PC上进行各种采样模式来让大尺度的自动驾驶场景合成成为可能。为了表达自动驾驶场景,我们提出了一个omega渲染网络来从稀疏点云中学习神经网络描述。我们的模型不只可以生成真实的驾驶场景,也可以将缝合、编辑驾驶场景。实验证明我们的模型可在大尺度驾驶场景中表现非常好。 Synthesizing free-view photo-realistic images is an important task in multimedia. With the development of advanced driver assistance systems~(ADAS) and their applications in autonomous vehicles, experimenting with different scenarios becomes a challenge. Although the photo-realistic street scenes can be synthesized by image-to-image translation methods, which cannot produce coherent scenes due to the lack of 3D information. In this paper, a large-scale neural rendering method is proposed to synthesize the autonomous driving scene~(READ), which makes it possible to synthesize large-scale driving scenarios on a PC through a variety of sampling schemes. In order to represent driving scenarios, we propose an {\omega} rendering network to learn neural descriptors from sparse point clouds. Our model can not only synthesize realistic driving scenes but also stitch and edit driving scenes. Experiments show that our model performs well in large-scale driving scenarios.
打开封面
下载高清视频
观看高清视频
视频下载器
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[Neural Rendering,任意拓扑重建] 香港大学、腾讯游戏、普朗克研究院等提出NeuralUDF,用来重建衣物等任意拓扑曲面的方法,弥补SDF不足
[NeRF进展] 浙江大学、阿里提出Mirror-NeRF,可以学习镜子准确的几何和反射效果,并可以支持多种不同的场景操控应用,如在场景中添加物体或镜子等
[NeRF进展,开源大规模场景] DNMP(同济、港中文、上海AI实验室,CPII),一种使用可变形神经mesh的,高质量快速的重建和渲染城市级别神经场的方法
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF编辑] 腾讯Pixel Lab,上科大提出Neural Imposters,一种将四面体网格与隐式表达混合的方法,可以实现神经场的编辑和控制操作
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[NeRF编辑进展,开源] Seal-3D(浙江大学CS&AUS, CAD&CG实验室),一种可让用户自由在像素级别NeRF编辑的方法,并可实时预览编辑结果
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[NeRF,超高清渲染方向]阿里提出4K级别的超高清NeRF训练和渲染方法,在主观和客观质量评价下都取得了很好的效果
[NeRF App] Luma AI推出新APP:Flythroughs,unbounded场景通过iPhone即可完成建模和漫游,已经发布上线,可开放体验
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,物体相机] MIT与莱斯大学脑洞大开:ORCa,将有光泽的物体转为神经场相机,将反光的不可见场景建模,可以看到物体看到的而不是相机看到的场景
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF纹理生成,SIGGRAPH] 中科院,腾讯等提出NeRF-Texture,从多视角图像采集和生成纹理,可应对如草、叶子、纺织品等3D空间复杂纹理生成
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[动态NeRF进展] 三星尖端技术研究院提出时域插值动态NeRF方法,通过在时域进行特征向量插值,构建动态场景的神经网络表达,训练速度与质量大幅度提升
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[3D特征] 克莱姆森大学,微软,CMU提出CVRecon,一个新的端到端 的3D神经重建框架,挖掘cost volume中的几何信息,提供了优质的3D特征
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[点云+神经渲染进展] Apple, CMU, UBC提出Pointersect,给定一个点云,在不转换为其他表达的情况下,进行推理光线与表面相交性
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
[NeRF 3D场景理解] UC伯克利、Luma AI提出GARField,使用辐射场对任何事物进行分组,从姿势图像输入分解为具有语义意义的组的层次结构的方法
[NeRF进展]上海交通大学、阿里提出CageNeRF,操纵三维NeRF的自适应笼子方法,让任意NeRF建模物体动起来(NeurIPS 2022)
[3DGan进展] nVidia, UCSD提出新的3D GAN方法,无监督地将神经体积渲染缩放到原始2D图像的更高分辨率,生成超细粒度3D几何效果
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展] 图宾根大学、Google提出Binary Opacity Grids,加强版本BakedSDF,生成视图质量更高,移动设备场景实时渲染
[NeRF+强化学习]柏林工业大学、MIT、Google使用NeRF监督强化学习agent的方法,加强自动物体操控能力(NeurIPS 2022)
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF+Diffusion进展] nVidia,多伦多大学等推出NeuralField-LDM,使用神经场和生成模型解决复杂开放世界3D场景的建模和编辑能力
[动态3DGS与场景编辑] 请香港大学黄熠华博士一起讲讲SC-GS和Deformable 3DGS两项工作