V
主页
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
发布人
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (NeurIPS 2022) Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo-Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J. Fleet, Mohammad Norouzi (Google Research Brain Team) 参考实现:https://github.com/lucidrains/imagen-pytorch 项目主页:https://imagen.research.google/ 文章两个创新点(实际上也因为这些点不够强而被质疑) 1. 将大语言预训练模型与diffusion模型结合,实现更好的效果 2. 使用动态阈值(dynamic thresholding)来训练模型 3. 框架相比DALL-E更简单清晰 我们推出Imagen,一个文字到图片的扩散模型,可以达到前所未有的真实感和对语言的深度理解。Imagen在强大的语言transformer模型基础上,深度理解输入文本内容,增强扩散模型在高保真度的图片生成。我们核心的发现是在一个通用的,仅通过文本语料预训练的大语言模型(比如Google的T5),在图片生成的编码文本过程中展现出了令人惊讶的好效果:在Imagen中提升了文本模型的大小,相比其他通过提升图片扩散模型本身的大小的方法,对生成图片保真度和图片与文本的呼应关系都提升更大。在COCO数据集上,Imagen达到了最优的7.27 FID打分,甚至都没有在COCO数据集上进行训练。在人类主观打分中发现Imagen样本与COCO数据集所标记的图片与文字的对齐程度是相当的。为了在更深度地评估文字到图片的转换,我们提出了DrawBench,一个对文字转图片的综合的对比打分标准。使用DrawBench,我们将Imagen与其他的近期的方法,如VQ-GAN+CLP,Latent Diffusion模型,以及DALL-E 2进行并排比较,发现人类打分判断Imagen在图片质量和图片文字对应效果上表现都要更优。 We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g., T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment....
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
【毕设有救了】终于有人把OpenCV最新最全实战项目讲清楚了,学习计算机视觉图像处理必备,练完即可毕业,毕设有救了
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
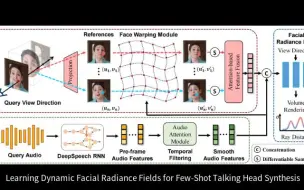
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[神经渲染进展,人体与物体合成] 首尔大学、Meta提出NCHO,一种将人体与物体组合,且反应物理接触关系变化的无监督学习模型,支持重新组合与动画效果
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
I3D 2023 Papers Session 1 - Neural Rendering and Image Warping
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[3D表达进展]密西根大学提出Neural Shape Compiler,可以实现文本、点云和程序间统一的转换框架,在多种3D表达任务中达到提升
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[NeRF+Diffusion进展] nVidia,多伦多大学等推出NeuralField-LDM,使用神经场和生成模型解决复杂开放世界3D场景的建模和编辑能力
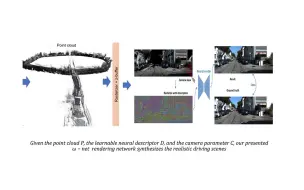
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[Diffusion进展,文本生成360度体验] Intel提出LDM3D,使用文本生成RGBD图,并将RGBD图渲染为360度三维体验感内容
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型