V
主页
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
发布人
AdaNeRF: Adaptive Sampling for Real-Time Rendering of Neural Radiance Fields (ECCV 2022) Andreas Kurz, Thomas Neff (Graz University of Technology, Austria), Zhaoyang Lv, Michael Zollhöfer(Reality Labs Research, USA), Markus Steinberger Github地址:https://github.com/thomasneff/AdaNeRF 新视角生成的问题已经革命性的通过对稀疏的场景观察结果来学习到它们的NeRF表达来完成。然而,使用这种方法渲染新图片仍然非常慢,这是因为获得体渲染方程的精确解需要每条光线的大量的样本数据计算。之前对于渲染性能的优化聚焦在对每一个关联采样点加速网络的计算过程,比如通过缓存radiance数据到单独外部的空间数据表达。但这样做导致模型的不紧凑。我们通过学习如何最佳缩减所需采样点数,提出了一个新的双正交网络架构。我们把网络分成可联合训练的采样网络(sampling network)和着色网络(shading network)。训练方法在同一条光线上使用固定的采样位置,并在这个基础上增量地引入各处稀疏的训练方法,在极低的采样数情况下,达到了非常高的质量。在精调后,这个紧凑神经网络表达达到实时渲染效果。实验显示本方法相比其他紧凑神经网络模型在质量和渲染帧率更加强大,相比其他复杂混合模型效果相当。 Novel view synthesis has recently been revolutionized by learning neural radiance fields directly from sparse observations. However, rendering images with this new paradigm is slow due to the fact that an accurate quadrature of the volume rendering equation requires a large number of samples for each ray. Previous work has mainly focused on speeding up the network evaluations that are associated with each sample point, e.g., via caching of radiance values into explicit spatial data structures, but this comes at the expense of model compactness. In this paper, we propose a novel dual-network architecture that takes an orthogonal direction by learning how to best reduce the number of required sample points. To this end, we split our network into a sampling and shading network that are jointly trained. Our training scheme employs fixed sample positions along each ray, and incrementally introduces sparsity throughout training to achieve high quality even at low sample counts. After fine-tuning with the target number of samples, the resulting compact neural representation can be rendered in real-time. Our experiments demonstrate that our approach outperforms concurrent compact neural representations in terms of quality and frame rate and performs on par with highly efficient hybrid representations.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
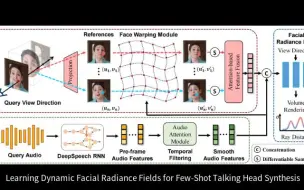
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展]上海交通大学、阿里提出CageNeRF,操纵三维NeRF的自适应笼子方法,让任意NeRF建模物体动起来(NeurIPS 2022)
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
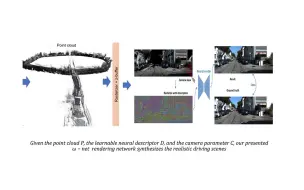
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,实时动态、静态6-DoF视频渲染]CMU, Meta等联合推出HyperReel,在低内存消耗下,实现实时的、高质量的、高分辨率的体渲染方法
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF+强化学习]柏林工业大学、MIT、Google使用NeRF监督强化学习agent的方法,加强自动物体操控能力(NeurIPS 2022)
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展] Oppo, Buffalo, 上科大提出NeuRBF,使用自适应的RBF进行神经场表达,相比INGP, TensoRF等取得更好的渲染效果
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展,Relighting方向] 浙江大学,MSRA等提出一种新的可重光照的NeRF的表达,通过向MLP提供多种hint,实现不同光照效果
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展] Google,图宾根大学等提出SMERF,支持实时、大规模场景漫游的,可流式传输的,存储高效的NeRF,可在各设备浏览器中实时渲染
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
CVPR24 最佳学生论文:实现3DGS新突破,任意尺度无锯齿渲染!三名华人学者参与!
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好