V
主页
[3D表达进展]密西根大学提出Neural Shape Compiler,可以实现文本、点云和程序间统一的转换框架,在多种3D表达任务中达到提升
发布人
Neural Shape Compiler: A Unified Framework for Transforming between Text, Point Cloud, and Program(ECCV 2022 workshop, Learning to Generate 3D Shapes and Scenes) Tiange Luo, Honglak Lee, Justin Johnson (密西根大学) 项目主页:https://tiangeluo.github.io/projectpages/shapecompiler.html 3D形状有互补的抽象信息,它们从底层几何信息和层次信息,到语言文本,它们可以传达各层的信息。这个工作提出了一个统一的框架来将各种形状的抽象进行互相之间的翻译(文本 ⬌ 点云 ⬌ 程序)。我们提出Neural Shape Compiler,来将抽象信息的转换变成一个条件生成过程。它将三种3D形状的抽象类型整合为一个统一的离散shape code,通过ShapeCode Transformer进行互转,然后将他们解码到一个目标的形状抽象中。Point Cloud Code是通过一个类别不可知的Point_VQVAE方法来获得的。在Text2Shape,ShapeGlot, ABO, Genre和Program Synthetic数据集上,Neural Shape Compiler都展示了在文本到点云,点云到文本,点云到程序和点云自动完成工作上强劲的优势。另外,Neural Shape Compiler可以通过联合训练各种异构数据和任务进行提升。 3D shapes have complementary abstractions from low-level geometry to part-based hierarchies to languages, which convey different levels of information. This paper presents a unified framework to translate between pairs of shape abstractions: _Text_ ⬌ _Point Cloud_ ⬌ _Program_. We propose **Neural Shape Compiler** to model the abstraction transformation as a conditional generation process. It converts 3D shapes of three abstract types into unified discrete shape code, transforms each shape code into code of other abstract types through the proposed ShapeCode Transformer, and decodes them to output the target shape abstraction. Point Cloud code is obtained in a class-agnostic way by the proposed _Point_VQVAE. On Text2Shape, ShapeGlot, ABO, Genre, and Program Synthetic datasets, Neural Shape Compiler shows strengths in _Text_ → _Point Cloud_, _Point Cloud_ → _Text_, _Point Cloud_ → _Program_, and Point Cloud Completion tasks. Additionally, Neural Shape Compiler benefits from jointly training on all heterogeneous data and tasks.
打开封面
下载高清视频
观看高清视频
视频下载器
[Neural Rendering,任意拓扑重建] 香港大学、腾讯游戏、普朗克研究院等提出NeuralUDF,用来重建衣物等任意拓扑曲面的方法,弥补SDF不足
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF,三维风格化效果] NeRF-Art是由香港城市大学、香港理工大学、Snapchat、USC、微软等联合推出的文本驱动生成的NeRF风格化方法
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
啊?几百块的KPA青春版?
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF编辑] 腾讯Pixel Lab,上科大提出Neural Imposters,一种将四面体网格与隐式表达混合的方法,可以实现神经场的编辑和控制操作
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
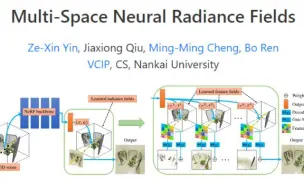
[NeRF进展,反射折射物体表达] 南开大学提出MS-NeRF,一种针对场景中反射和折射物体表达和渲染的方法,低消耗地提升NeRF模型,对相应场景效果提升显著
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[点云+神经渲染进展] Apple, CMU, UBC提出Pointersect,给定一个点云,在不转换为其他表达的情况下,进行推理光线与表面相交性
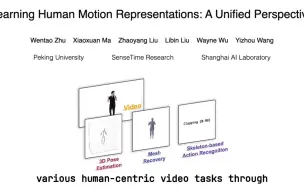
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[AIGC进展,使用shape+文本生成纹理] 特拉维夫大学提出TEXTure,通在已知3D shape情况下,使用文本可生成、编辑和迁移纹理效果
[Diffusion进展,文本转视频]新加坡国立大学、腾讯ARC实验室提出Tune-A-Video,使用文本生成图片模型One-Shot精调至视频,效果很棒
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
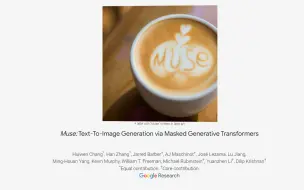
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[Diffusion生成NeRF] TUM, Apple提出HyperDiffusion,用Diffusion计算神经场权重,统一框架下生成3D权重或4D动画
[NeRF进展,单图实时3D画像] UCSD, nVidia,斯坦福提出LP3D,使用无姿态单图,实时推理和渲染真实感3D表达,合成高质量3D画像
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF进展,效果提升] TUM与Meta推出GANeRF,使用GAN来解决视角观察缺陷以及小的光照变化带来的重建质量不佳问题,提升1.4dB以上
[Mesh进展] nVidia,多伦多大学提出FlexiCubes,使用isosurface或标量场迭代优化3D表面Mesh,相比MC和DMTeT取得巨大提升
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
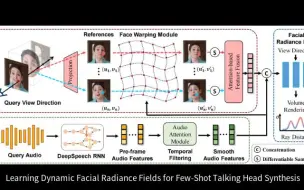
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF+文本转3D] nVidia,多伦多大学Sanja团队:ATT3D,在一秒内使用文本生成3D的方法,极大提升了生成速度,并可完成简单的3D转换型动画
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF,超高清渲染方向]阿里提出4K级别的超高清NeRF训练和渲染方法,在主观和客观质量评价下都取得了很好的效果
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影