V
主页
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
发布人
MVImgNet: A Large-scale Dataset of Multi-view Images Xianggang Yu, Mutian Xu, Yidan Zhang, Haolin Liu, Chongjie Ye, Yushuang Wu, Zizheng Yan, Chenming Zhu, Zhangyang Xiong, Tianyou Liang, Guanying Chen, Shuguang Cui, Xiaoguang Han(香港中文大学,理工学院、未来智联网络研究院) 项目主页:https://gaplab.cuhk.edu.cn/projects/MVImgNet/#table_stat Github主页:https://github.com/GAP-LAB-CUHK-SZ/MVImgNet Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while...
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[点云+神经渲染进展] Apple, CMU, UBC提出Pointersect,给定一个点云,在不转换为其他表达的情况下,进行推理光线与表面相交性
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[NeRF进展,交互编辑方向] Inria, 马克斯普郞克学院提出NerfShop,使用基于Cage变形的方法进行物体的交互式选择与编辑,进一步推动实用
TBC 2023 点云高级过滤
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频
[动态NeRF进展] 三星尖端技术研究院提出时域插值动态NeRF方法,通过在时域进行特征向量插值,构建动态场景的神经网络表达,训练速度与质量大幅度提升
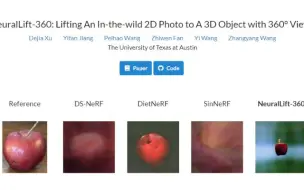
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
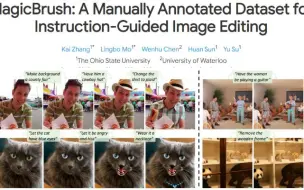
[数据集] 俄亥俄州立大学、滑铁卢大学:MagicBrush,一个人工标记的数据集,用来训练文本驱动的图片编辑,并精调instructPix2Pix验证了效果
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[神经渲染进展,人体与物体合成] 首尔大学、Meta提出NCHO,一种将人体与物体组合,且反应物理接触关系变化的无监督学习模型,支持重新组合与动画效果
[NeRF进展,物体相机] MIT与莱斯大学脑洞大开:ORCa,将有光泽的物体转为神经场相机,将反光的不可见场景建模,可以看到物体看到的而不是相机看到的场景
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,单图片生成多视角] Apple, UC圣迭戈分校,马普所,宾大发布NerfDiff,使用CDM+NeRF提高生成质量与效果
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
[NeRF进展,动态NeRF编码与串流] 上海科技大学、NeuDim推出ReRF,通过设计辐射场编码Codec,实现FVV长内容低码率编码与实时传输与播控
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF进展,编辑方向] 三星多伦多AI中心,多伦多大学,约克大学等:SPIn-NeRF,可快快速完成3D Segmentation和Inpainting任务
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域