V
主页
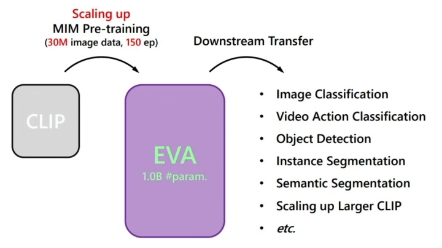
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
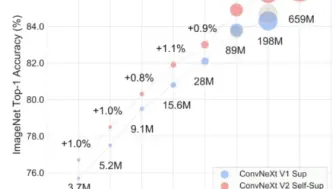
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
【多模态+大模型+知识图谱】2024最好创新的研究方向!绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
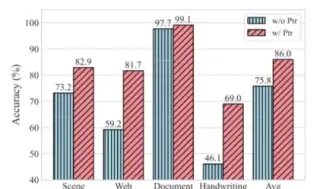
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
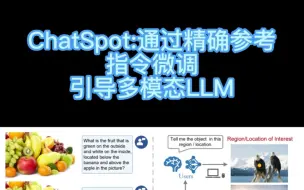
ChatSpot:更精确的带参考坐标多模态指令微调,目前已开源!#计算机 #论文 #nlp #ai #chatgpt
任意文献PDF内容,30秒自动生成思维导图,助力科研学习每一天!
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
基于Diffusion模型的DiffFace来了,交换效果超过之前的经典模型!代码和模型即将开源!
基于深度学习的视频文本的跨模态检索30页综述来了,包含近7年150篇相关论文!
Meta AI提出新的视觉Transformer结构,相同精度内存减少15倍!代码和模型目前已开源!
微软联合北大提出了首个用于音视频联合生成的多模态扩散模型MM-Difussion!可以给定视频生成音频或给定音频生成视频!
【脑客中国·科研】第155位讲者 | 王杰:多模态磁共振成像与脑科学
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
麻省理工又上干货!2024MIT基础模型和生成式人工智能入门课程!——人工智能/生成式AI/机器学习/深度学习
【EMNLP2023】清华联合阿里提出了利用大型语言模型辅助多模态OOD检测的新方法!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
Adobe提出基于预训练图像Diffusion模型的视频编辑器,无需训练即可完成视频编辑功能,效果超过Tune-a-Video等方法!
微软提出简单的Open vocabulary检测和分割框架,能够统一处理两种任务,性能超过GLIP等模型!目前已开源!
腾讯优图提出啄木鸟(Woodpecker):无需训练即可矫正多模态大语言模型的幻觉问题!
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!
原来AI真的能生成高颜值美女,快来试试多模态生成模型吧!
【多模态大模型入门课程】多模态基本架构 图文匹配原理 文生图DALL·E模型 GPT4模型原理讲解 多模态图像融合
阿里达摩院提出新的视频文本预训练框架,通过预训练,其在视频下游任务取得多项SOTA!
ChatGPT 越狱模式正式启动!学术版更新语音朗读功能并支持同时询问多个AI模型
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
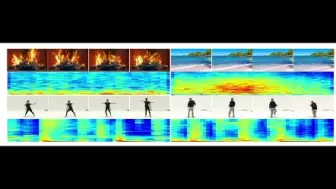
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
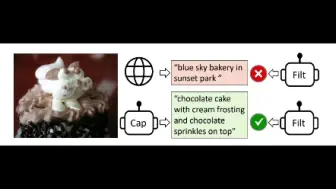
来自真实用户的百万级文本视频数据!Sora时代的视频生成数据集VidProM开源了!
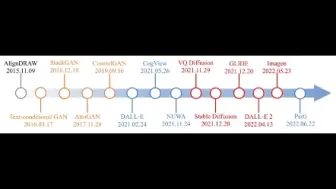
基于Diffusion模型的以文生图综述来了!包含145篇相关论文,涉及Diffusion相关理论和基础介绍!
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
[理解和生成]的大一统,微软提出BLIP多模态模型,取得下游多项任务SOTA!
Adobe提出超越Stable Diffusion的GAN网络,10亿参数量模型速度吊打Stable Diffusion!目前已被CVPR2023接收!
AI 快速生成论文写作框架!
腾讯提出一种新的CLIP模型,利用更加soft的跨模态对齐策略,提升CLIP在各项任务上的性能!