V
主页
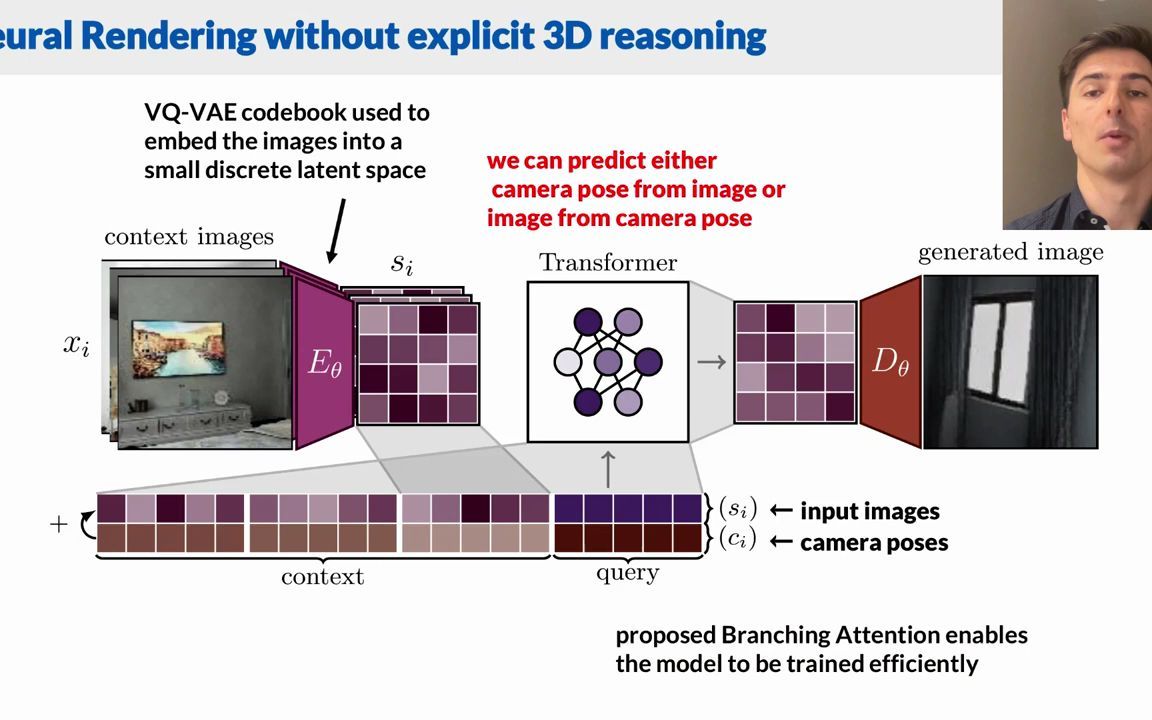
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
发布人
Jonas Kulhanek,Erik Derner,Torsten Sattler (Czech Technical University),Robert Babuska(Czech Technical University, Delft University of Technology) 项目Github地址:https://github.com/jkulhanek/viewformer 下载不到请私信或评论留个邮件 新视角生成问题是一个长期存在的问题。难以全面解决。我们在本项目中,考虑这个问题的一个变种:即当我们只有对一个场景或物体的少量上下文视角的稀疏表达时,是否可以更有效的进行视角生成。我们的目标是对场景进行新视角的预测,这样就需要对先验知识进行学习。目前最先进的技术是基于NeRF的,也得到了非常好的效果。它的问题在于,对于每张图片,都需要通过神经网络计算数百万计的3D点样本数据,计算时间会非常长。我们提出了一个基于2D的方法,它将多个上下文视角和需要生成的新图片的姿势,通过神经网络的一个单pass映射为一张新图片。 我们的模型设计为一个由码本(codebook)和transformer模型组成的两阶段的架构。码本是用来将各图片向量化到一个更小的隐空间,transformer模型是用来在这个更紧凑的空间中完成视角合成工作。为了有效的训练我们的模型,我们提出了一种新的分支注意力机制,它使我们使用同一个模型完成神经网络渲染和相机姿态估计两个任务。对真实场景的实验证明我们的方法相比基于NeRF的渲染方法而言,不仅效果是与之相当的,而且训练速度和视角生成速度都快数十倍。 Novel view synthesis is a long-standing problem. In this work, we consider a variant of the problem where we are given only a few context views sparsely covering a scene or an object. The goal is to predict novel viewpoints in the scene, which requires learning priors. The current state of the art is based on Neural Radiance Field (NeRF), and while achieving impressive results, the methods suffer from long training times as they require evaluating millions of 3D point samples via a neural network for each image. We propose a 2D-only method that maps multiple context views and a query pose to a new image in a single pass of a neural network. Our model uses a two-stage architecture consisting of a codebook and a transformer model. The codebook is used to embed individual images into a smaller latent space, and the transformer solves the view synthesis task in this more compact space. To train our model efficiently, we introduce a novel branching attention mechanism that allows us to use the same model not only for neural rendering but also for camera pose estimation. Experimental results on real-world scenes show that our approach is competitive compared to NeRF-based methods while not reasoning explicitly in 3D, and it is faster to train.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展] MoFaNeRF,基于NeRF的面部可变形模型,让面部拟合、生成、面部绑定、面部编辑更容易,效果更好(ECCV 2022)
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展] 神经网络反向渲染的多视角光度立体视觉算法 (ECCV 2022)
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM
[NeRF+Diffusion进展,无条件或单视角重建] 同济大学、Apple等提出SSDNeRF,使用单阶段扩散prior生成NeRF,支持无条件或单视角重建
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
比喝水还简单!2024年最详细的【大模型自学路线图】整理出来啦!迪哥手把手教你最高效的大模型学习方法,轻松搞定AIGC大模型!(大模型训练/大模型微调)
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
【2024最全实战项目】整整100个PyTorch练手项目合集,学习PyTorch入门小白最新版全套教程必备,练完即可毕业,练手项目~项目经验~毕设/课设
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,few-shot重建,群友工作] UCLA, nVidia提出FreeNeRF,一个关键观察触发了一个极简的优化,使少量视角重建效果大幅度提升
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,单图片生成多视角] Apple, UC圣迭戈分校,马普所,宾大发布NerfDiff,使用CDM+NeRF提高生成质量与效果
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
终于找到了这个逐行解读代码的网站!全网近百万大学生研究生收藏!github标星超55.6k!----机器学习/深度学习/CV/NLP
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
【全122集】冒死上传!CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气全部学完!
(强推)Transformer模型最通俗易懂的讲解,零基础也能听懂!看计算机大佬如何讲解Transformer原理!(人工智能、深度学习、机器学习、图像处理)
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
[NeRF进展,渲染质量提升] Google NeRF的几位创始人:Zip-NeRF,解决Mip-NeRF 360锯齿问题,复杂场景渲染提升,训练速度提升22倍
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
【122集付费!】CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气全部学完!
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
AI 眼中的体操项目
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
跟着李沐读论文!【多模态论文串讲】这可能是目前为把多模态内容讲的最简单易懂的教程了吧!(Openai CLIP模型、对比学习、对比学习、Diffusion模型)
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
超全超简单!一口气刷完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM七大深度学习神经网络算法!真的比刷剧还爽!(人工智能\机器学习)
2024年完整的人工智能入门指南
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案