V
主页
京东 11.11 红包
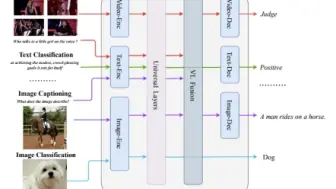
上海交大学者提出了第一个用于医学图像诊断的多模态ChatGPT模型,在各种医学诊断任务上取得SOTA!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
超越GPT-4o!Allen AI重磅发布Molmo:最强多模态AI模型!碾压Llama 3.2!
强强联合!又一个容易出成果的方向-多模态医学处理!值得每一个医学生发论文的好方向!
YOLOv10多模态 结合Transformer与NMS-Free 融合可见光+红外光(RGB+IR)双输入【代码见评论区】
Scratch 神经网络 图像识别
深度学习BIBM2024 | 医学图像分割 | SMAFormer
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
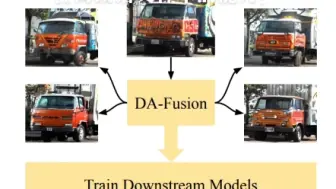
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
【全568集】清华大佬一周讲完的AI大模型,通俗易懂,2024最新版!7天学完从入门到进阶实战,专为零基础小白研制AI大模型课程,存下吧,很难找全了!!
[理解和生成]的大一统,微软提出BLIP多模态模型,取得下游多项任务SOTA!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
强推!不愧是李飞飞,一口把深度学习、计算机视觉、神经网络、图像处理、图像分割、目标检测、物体识别给讲透了,新手小白秒上手!-人工智能/计算机视觉
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
ECCV 2024 英伟达提出SAL:激光雷达分割一切!自动驾驶感知新技术!
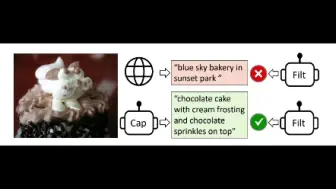
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!
特斯拉发布会,和特斯拉机器人玩石头剪刀布
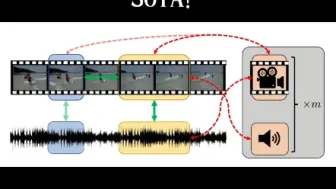
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
13分钟速通yolov11,使用自己的数据集从环境搭建到模型训练、推理、导出
O1:模型认知智能的突破
代码原理讲解|特征点位置信息模块 图像通用 超详细版 CCF-A 浙大开源!【V1代码讲解020】
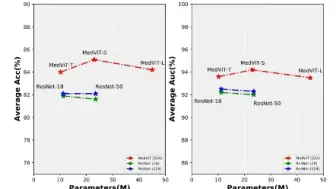
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
YOLOv8+PSMNet+Deepsort,实现目标检测、追踪和测距!
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
O1大模型背后的原理以及带来的趋势
腾讯提出一种新的CLIP模型,利用更加soft的跨模态对齐策略,提升CLIP在各项任务上的性能!
代码原理讲解|跨模态一致性增强 超详细版 CCF-A 浙大开源!【V1代码讲解018】
“AI读心术”来了,日本学者基于Stable Diffusion模型提出了一个大脑视觉信号重建图像的研究,效果惊人!目前已被CVPR 2023接收!
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
【国内白嫖】10月1日最新ChatGPT4.0随便用
Mistral AI重磅推出Pixtral 12B开源多模态大模型!vLLM部署Pixtral轻松实现视频智能分析,打造你的AI视觉助手-从图像识别到视频分析
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
Meta 碾压 OpenAI? MovieGen 模型简单粗暴才是王道?
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
YOLOv11涨点改进| ECCV 2024| DHSA有效涨点注意力即插即用模块,正确使用轻松暴涨5个点,图像恢复,目标检测,图像分割,图像增强等所有CV任务
三贱客,瞎聊什么是多模态大模型!
ChatGPT4.0 学术版、公开版、知识库应用平台新增任意网页、视频分析模型!
SAM2真的很容易出创新!无需微调既能小样本医疗图像分割
Meta重磅发布Llama 3.2:推动轻量级AI模型与多模态模型的全面应用
知识库应用平台,国庆大版本更新啦!
北大提出金字塔流匹配算法用于高效视频生成(今日Arxiv 10月10日)2024年10月10日Arxiv cs.CV发文量约226余篇,减论Agent