V
主页
亚马逊联合牛津提出了用于多模态理解的三元对比学习TCL,在CLIP的基础上提升了多模态模型的跨模态理解能力!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
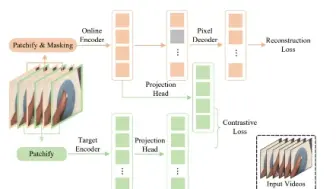
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
InternVL 多模态模型语音功能小剧透!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
我们把ALOHA机器人和多模态大模型结合了起来,来看看效果如何?
精选【人工智能课程】大模型时代 如何学习人工智能?零基础学习教程!人工智能学习路线 人工智能就业方向 人工智能 大模型 多模态技术路线 人工智能项目开发
微软联合北大提出了首个用于音视频联合生成的多模态扩散模型MM-Difussion!可以给定视频生成音频或给定音频生成视频!
斯坦福大学AI博士,揭秘最新多模态AI - 杨俊睿 Jackie,MAUI
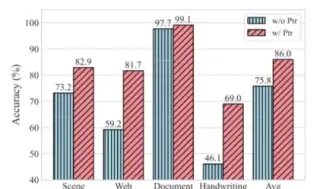
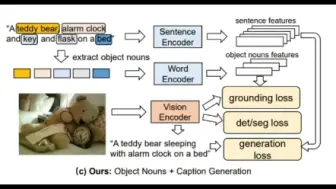
亚马逊学者提出了既能看又能读的多模态场景理解模型,支持传统的VQA以及文本VQA!
字节联合爱丁堡大学学者提出新的多模态预训练方法MUG,结合MAE和Caption生成
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!
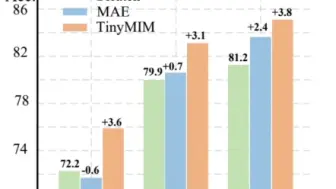
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
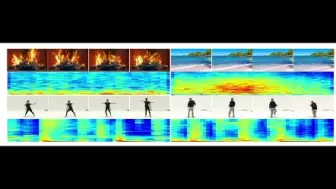
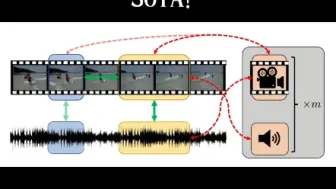
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
国内智驾老兵百度开源BEVWorld:通过统一BEV潜在空间实现自动驾驶的多模态世界模型
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
字节联合浙大提出新的视频语言预训练模型TemPVL,能够显著提升下游多模态视频理解任务性能!
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
多模态大模型的幻觉类型和产生原因!大模型微调
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
NEURA 与 NVIDIA 携手重新定义机器人技术的未来!
鹏城实验室开放了45页多模态预训练大模型综述!总结了近5年多模态预训练相关的算法和数据!多模态预训练学习包!
字节联合南开大学提出了用于视频动作识别的自监督框架CMAE-V,融合了MAE和对比学习,在视频动作识别任务取得SOTA!
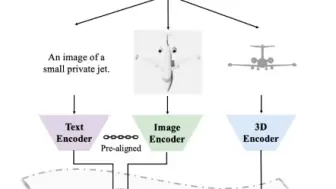
3D版CLIP横空出世,助力各种点云任务!涨点效果明显!
微软学者整理了100页图文多模态预训练综述,涉及各种多模态模型和应用,并且附带视频教程,需要的同学快来领取!
SAM+CLIP,会擦出什么样的火花!模型组合大法霸榜图像分割Zero-Shot!
Stability AI又放大招了!基于SD3蒸馏更快的文生图模型SD3-Turbo!
北大联合南洋理工提出了一种简单有效的开放词汇实例分割框架,分割效果惊艳!
字节联合爱丁堡大学提出新的视觉预训练方法MUG,取得新的SOTA!模型和代码均已开源,快来领取!
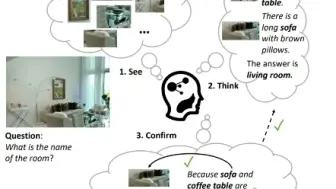
MIT联合清华提出基于知识的视觉推理多模态模型IPVR,模拟人类视觉推理,取得较好效果!
Sora展示会 Tim Fu AI视频创作,人工智能大模型多模态
腾讯联合新国立提出了一种one-shot文本生成视频的方法!效果超过CogVideo!代码和模型即将开源!
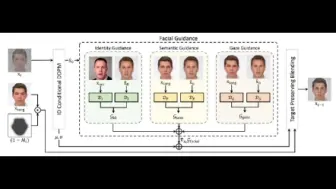
基于Diffusion模型的DiffFace来了,交换效果超过之前的经典模型!代码和模型即将开源!
上海AI Lab提出利用多种预训练模型进行集成学习的新方法CaFo,利用 GPT-3,CLIP,DINO等多种基础预训练模型提升少样本学习能力!
大模型其实没有逻辑能力!
【太强了】从入门到精通一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络!一点要看到最后(深度学习,AI)