V
主页
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/13_kd_pipeline.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
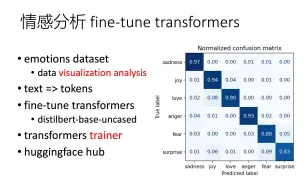
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
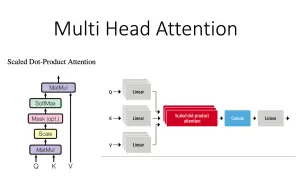
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
[LLMs 实践] 13 gradient checkpointing 显存优化 trick
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
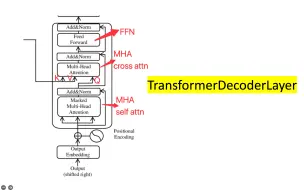
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[LLMs tuning] 04 optimizer Trainer 优化细节(AdamW,grad clip、Grad Norm)等
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
基于模糊PID的无刷直流电机控制系统设计simulink
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
[pytorch distributed] 03 DDP 初步应用(Trainer,torchrun)
[LLMs 实践] 11 gradient accumulation 显存优化 trick
[LLMs tuning] 05 StackLlama、SFT+DPO(代码组织、数据处理,pipeline)
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
【手推公式】从 logodds 到 sigmoid 概率化输出,用于 LR、XGBoost 的分类任务
[BERT 番外] Sin Position Encoding 的简洁实现(RoPE 基础)
[动手写 bert 系列] 解析 bertmodel 的output(last_hidden_state,pooler_output,hidden_state)
[动手写神经网络] 02 逐行写代码 CNN pipeline 图像分类(模型结构、训练、评估)
[sbert 01] sentence-transformers pipeline
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[personal chatgpt] peft LoRA merge pipeline(lora inject,svd)
[动手写 bert 系列] Bert 中的(add & norm)残差连接与残差模块(residual connections/residual blocks)
[动手写bert] bert pooler output 与 bert head
[pytorch distributed] accelerate 基本用法(config,launch)数据并行
[动手写 bert 系列] torch.no_grad() vs. param.requires_grad == False
[动手写 bert 系列] 02 tokenizer encode_plus, token_type_ids(mlm,nsp)
【手推公式】odds(几率)与对数几率(logodds)在logistics regression及xgboost classification中的应用
[动手写Bert系列] bertencoder self attention 计算细节及计算过程
[动手写 bert 系列] BertTokenizer subword,wordpiece 如何处理海量数字等长尾单词
[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节
[动手写 bert 系列] bert model architecture 模型架构初探(embedding + encoder + pooler)
[动手写 bert] masking 机制、bert head 与 BertForMaskedLM
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境