V
主页
[Generate AI进展,合成大规模无界3D场景] 南洋理工大学提出SceneDreamer,使用2D图片训练、使用随机噪声生成多样化无界3D场景
发布人
SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections Zhaoxi Chen, Guangcong Wang, Ziwei Liu(S-Lab, 新加坡南洋理工大学) In this work, we present SceneDreamer, an unconditional generative model for unbounded 3D scenes, which synthesizes large-scale 3D landscapes from random noises. Our framework is learned from in-the-wild 2D image collections only, without any 3D annotations. At the core of SceneDreamer is a principled learning paradigm comprising 1) an efficient yet expressive 3D scene representation, 2) a generative scene parameterization, and 3) an effective renderer that can leverage the knowledge from 2D images. Our framework starts from an efficient bird's-eye-view (BEV) representation generated from simplex noise, which consists of a height field and a semantic field. The height field represents the surface elevation of 3D scenes, while the semantic field provides detailed scene semantics. This BEV scene representation enables 1) representing a 3D scene with quadratic complexity, 2) disentangled geometry and semantics, and 3) efficient training. Furthermore, we propose a novel generative neural hash grid to parameterize the latent space given 3D positions and the scene semantics, which aims to encode generalizable features across scenes and align content. Lastly, a neural volumetric renderer, learned from 2D image collections through adversarial training, is employed to produce photorealistic images. Extensive experiments demonstrate the effectiveness of SceneDreamer and superiority over state-of-the-art methods in generating vivid yet diverse unbounded 3D worlds.
打开封面
下载高清视频
观看高清视频
视频下载器
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
我从来不用自己剪视频,因为我会用AI
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[Generative AI,自然场景生成] 山东大学、腾讯、北大提出Sin3DGen,一个3D生成模型,使用单个patch生成3D场景
[3D生成] 南洋理工、香港中文、上海AI实验室提出DiffTF,一个基于扩散模型和三平面的前馈框架,用于生成多样化的、大语料量规模的真实世界3D物体
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[数字人] 华中科大、南洋理工、大湾区大学等提出WildAvatar,开源的在不可控自然场景中,利用普通只能手机重建数字人形象的数据集和方法
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF+Diffusion进展] nVidia,多伦多大学等推出NeuralField-LDM,使用神经场和生成模型解决复杂开放世界3D场景的建模和编辑能力
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[NeRF进展,任意相机路径NeRF快速重建] 香港大学、南洋理工大学、马克斯普朗克等CVPR Highlight:F2NeRF,任意相机路径NeRF快速重建
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[数据集] 上海AI实验室、商汤等提出DNA-Rendering,一个多样化的,高精度,以人物为中心的,包含2D/3D人体关键点,前景mask等大规模人体数据集
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,开源大规模场景] DNMP(同济、港中文、上海AI实验室,CPII),一种使用可变形神经mesh的,高质量快速的重建和渲染城市级别神经场的方法
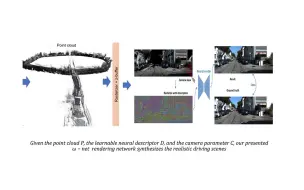
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
【Stable diffusion】AI生成视频再出王炸!SD文生视频横空出世!极度爆炸的视频生成!真的太实用了,这3个新功能一个比一个炸~(附插件)保姆级教程
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[NeRF进展,单图片生成多视角] Apple, UC圣迭戈分校,马普所,宾大发布NerfDiff,使用CDM+NeRF提高生成质量与效果
[Diffusion进展,文本生成360度体验] Intel提出LDM3D,使用文本生成RGBD图,并将RGBD图渲染为360度三维体验感内容
爆火!ReconX:3D场景重建新范式!输入两张图片,给你一个3D逼真场景!
[NeRF进展,大型城市场景建模] 香港中文大学、浙江大学、马克斯普朗克等发布GridNeRF,高效建模大规模真实感城市3D场景
【Stable Diffusion】太变态了,只需一个插件就能让图片变成视频、丝滑流程、鬼畜必备,SD教程、SD插件
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[AIGC进展,文本生成室内3D Mesh] 慕尼黑工业大学Matthias团队与密西根大学Justin团队,推出Text2Room,用文本生成室内3D场景建模
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展] CMU,亚琛工业大学,Inria提出动态3D高斯方法,将3D Gaussian Splatting扩展到动态场景,灵活支持多种下游应用
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF+自动驾驶] 浙大、图宾根大学提出PanopticNeRF360,将3D标记与带噪声的2D语义线索组合生成一致性全景标签和高质量任意视角图片的方法
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)