V
主页
[NeRF进展]上海交通大学、阿里提出CageNeRF,操纵三维NeRF的自适应笼子方法,让任意NeRF建模物体动起来(NeurIPS 2022)
发布人
Yicong Peng,Yichao YanShenqi Liu,Yuhao Cheng,Shanyan Guan(上海交通大学),Bowen Pan(阿里),Guangtao Zhai,Xiaokang Yang 作者知乎的过程描述,写的很详细:https://zhuanlan.zhihu.com/p/581808674 Github地址(目前代码还没有公开):https://github.com/PengYicong/CageNeRF 目前隐式表达相关技术在3D渲染上已经取得了非常好的效果,但在变形和动画上的进展仍然是非常有挑战性的。现有的工作都应用了模型依赖的变形先验数据来完成的,比如SMPL在人体动画上的使用。但是这样的技术因为对物体分类有先验知识要求,都是没有办法被通用化的。为了解决这个问题,针对任意通过NeRF学习重建的物体,我们提出了一个新的框架来对它们进行变形和动画。这里核心的洞察是我们提出了一个基于笼子的表达方式作为变形的先验知识,那这样就实现了物体分类无关的通用化。具体的讲,变形过程是通过在渲染空间中定义一个封闭的、基于稀疏约束的节点组成的多边形网格笼子,在变形时,将每个点重新投射到变形笼子里基于重心插值计算的新的位置的新节点。这样,我们就可以把笼子的变化设计为一个通用的约束,进而由它来变形和动画任意的目标物体,并且保持几何的细节信息。通过大量的实验,我们验证了本框架对于几何数据编辑、物体动画和变形相关的任务非常高效。 While implicit representations have achieved high-fidelity results in 3D rendering, deforming and animating the implicit field remains challenging. Existing works typically leverage data-dependent models as deformation priors, such as SMPL for human body animation. However, this dependency on category-specific priors limits them to generalize to other objects. To solve this problem, we propose a novel framework for deforming and animating the neural radiance field learned on arbitrary objects. The key insight is that we introduce a cage-based representation as deformation prior, which is category-agnostic. Specifically, the deformation is performed based on an enclosing polygon mesh with sparsely defined vertices called cage inside the rendering space, where each point is projected into a novel position based on the barycentric interpolation of the deformed cage vertices. In this way, we transform the cage into a generalized constraint, which is able to deform and animate arbitrary target objects while preserving geometry details. Based on extensive experiments, we demonstrate the effectiveness of our framework in the task of geometry editing, object animation and deformation transfer.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
[Neural Rendering,任意拓扑重建] 香港大学、腾讯游戏、普朗克研究院等提出NeuralUDF,用来重建衣物等任意拓扑曲面的方法,弥补SDF不足
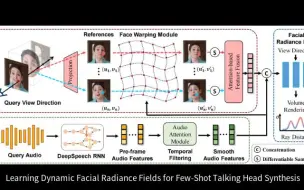
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF+强化学习]柏林工业大学、MIT、Google使用NeRF监督强化学习agent的方法,加强自动物体操控能力(NeurIPS 2022)
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
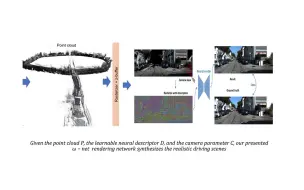
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[Diffusion+Transformer,人体动画进展] 阿里达摩院刚刚提出一个统一的预训练扩散模型MoFusion,用于人体动画合成 (arXiv)
[NeRF进展,时间一致动态场景重建] MPI, Meta提出SceNeRFlow,一种通用的,非刚性场景的,时间一致性的NeRF重建方法,可重建大尺度运动
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,Relighting方向] 浙江大学,MSRA等提出一种新的可重光照的NeRF的表达,通过向MLP提供多种hint,实现不同光照效果
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
在家作AI,昨天880,一台电脑,方法简单,分享我的接单平台、接单技巧和资源分享,目前经济自由!!
[AIGC进展,使用多种因素合成,提升合成控制力] 阿里与蚂蚁金服提出Composer,使用多种因素训练diffusion model,提高合成的组合能力和可控
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
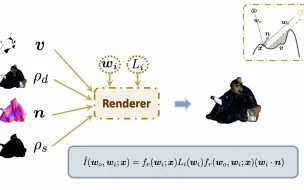
[NeRF进展] 神经网络反向渲染的多视角光度立体视觉算法 (ECCV 2022)