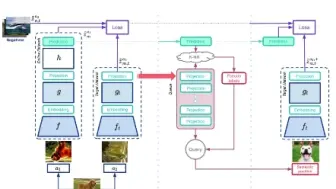
V
主页
京东 11.11 红包
字节联合北大提出新的用于卷积网络的掩码自监督预训练方案Spark,性能超越ConvNext V2!代码和模型目前已开源!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
百度联合VIS提出新的文档图像理解预训练框架StrucTextv2,设计了适用于文档数据的掩码自监督策略,目前已被ICLR 2023接收!
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
顶会爆款!LSTM魔改效果惊人,AI预测准确率攀升至90%!
全新的全卷积视觉骨干网FCViT,超过ConvNext,目前已开源!
DeepMind提出了新的半监督学习方法SEMPPL,结合当前的对比学习自监督学习方案,表征能力得到进一步提升!
阿里提出了一种联合多个语义分割数据集进行训练的语义分割方法LMSeg,相比单一数据集训练提升明显!
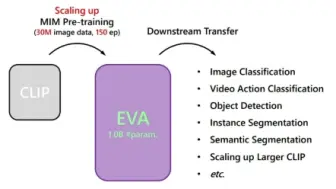
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
Self-Attenion的重思考,VIT更快的同时性能更强,Skip Attention通过减少注意力来提升VIT性能!
Nvidia联合Meta AI提出了基于Transformer的强大实例Mask生成框架MAL,仅使用Box标注即能达到接近Mask监督的效果!
腾讯提出一种新的CLIP模型,利用更加soft的跨模态对齐策略,提升CLIP在各项任务上的性能!
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
微软多模态团队提出了新的语言增强多模态预训练大模型,可以类似BLIP2进行多模态chat,效果很惊艳!
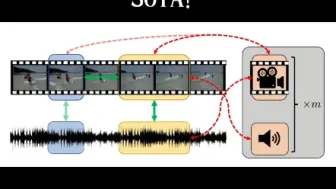
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
字节联合爱丁堡大学学者提出新的多模态预训练方法MUG,结合MAE和Caption生成
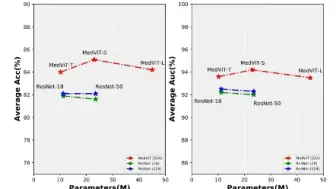
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
【全874集】目前B站最全最细的ChatGPT零基础全套教程,2024最新版,包含所有干货!一天就能从小白到大神!少走99%的弯路!存下吧!很难找全的!
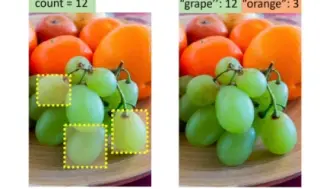
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
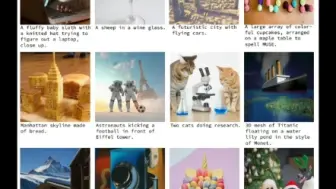
谷歌基于掩码Transformer提出新的以文生图SOTA模型Muse!生成效果和效率大幅超过Difussion模型和自回归模型!
为什么神经网络可以学习任何东西?首次使用动画讲解,带你吃透神经网络!(CNN卷积神经网络、RNN循环神经网络、GAN生成式对抗网络、人工智能、AI)
Transformer能做逻辑推理吗?不曾展露的真实实力可能被你忽略了!看完这篇顿悟!
Switch AI男变身女 AI制作
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
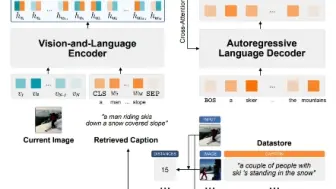
里斯本大学学者提出检索增强的Image Captioning 方法,可以在预训练图文编码器的基础上进一步提升Caption性能!
Meta AI提出新的视觉Transformer结构,相同精度内存减少15倍!代码和模型目前已开源!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
何恺明新作出炉!异构预训练Transformer颠覆本体视觉学习范式,AI性能暴涨超20%
腾讯联合新国立提出了一种one-shot文本生成视频的方法!效果超过CogVideo!代码和模型即将开源!
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
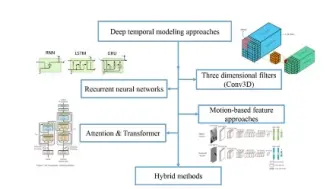
动作识别最新综述来了,包含RNN,3D卷积以及Transformer等算法,涉及近300篇相关论文!
YOLO V6卷土重来,开源了3.0版本!检测性能超过YOLOX以及PP-YOLOE,达到YOLO系列新SOTA!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
神经网络杀疯了,登上nature:35年首次被证明具有泛化能力,能像人类一样思考!人工智能/机器学习/神经网络/深度学习/计算机视觉
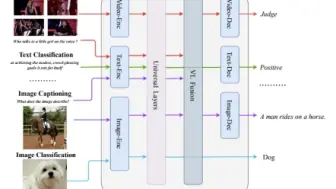
CVPR2023 基于掩码的视觉和语言Transformer,能够同时完成以文生图和Image Captioning两种多模态生成任务,且效果非常不错!
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
即插即用特征融合模块CAFM,即用即涨点
【人工智能基础】第51讲:Transformer模型(1)-张宏利主讲
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!