V
主页
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
InternVL 多模态模型语音功能小剧透!
腾讯提出一种新的CLIP模型,利用更加soft的跨模态对齐策略,提升CLIP在各项任务上的性能!
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
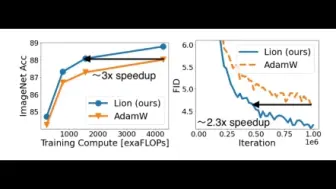
最强优化器来了!谷歌提出适用于多种任务的新型优化器Lion,在多项任务上以更快的训练速度取得更好的性能!目前已开源!
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
阿里达摩院提出新的视频文本预训练框架,通过预训练,其在视频下游任务取得多项SOTA!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
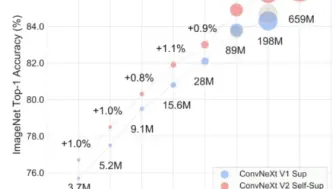
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
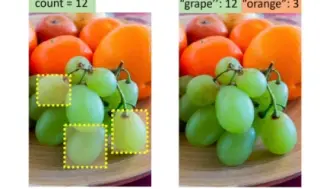
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
上海交大学者提出了第一个用于医学图像诊断的多模态ChatGPT模型,在各种医学诊断任务上取得SOTA!
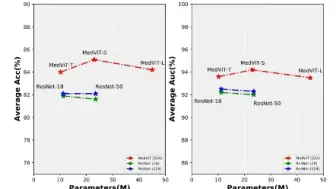
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
AI生成剧烈运动视频,大翻车引起大佬热议, 到底是什么原因造成的?
字节提出新的多边形战士,通用基础模型X-FM,将视觉,文本和多模态的训练做到了一个阶段,在多项下游任务表现不错!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
华为诺亚实验室提出NLIP多模态模型:仅用2900万数据性能超过BLIP和CLIP等亿级数据训练的多模态模型!
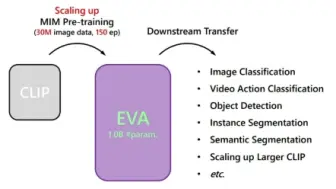
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
世界不再有长期,因为五年后的世界将大变样!人工智能
04_多模态_基于vLLM进行模型推理与源码讲解
商汤科技提出具有双层路由注意力的视觉Transformer,减少原始ViT计算量的同时性能大幅超过Swin Transformer!已被CVPR 2023接收!
多模态大模型的幻觉类型和产生原因!大模型微调
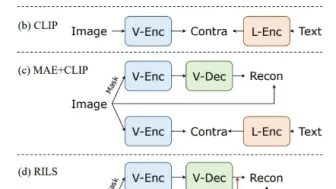
腾讯结合了MAE和CLIP,提出了新的在语言语义上进行掩码重建的预训练框架RILS,超过多种视觉预训练和多模态预训练方案!
NEURA 与 NVIDIA 携手重新定义机器人技术的未来!
斯坦福大学AI博士,揭秘最新多模态AI - 杨俊睿 Jackie,MAUI
国内智驾老兵百度开源BEVWorld:通过统一BEV潜在空间实现自动驾驶的多模态世界模型
微软多模态团队提出了新的语言增强多模态预训练大模型,可以类似BLIP2进行多模态chat,效果很惊艳!
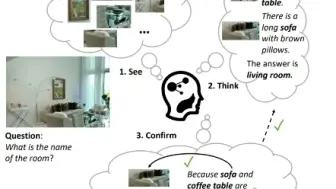
MIT联合清华提出基于知识的视觉推理多模态模型IPVR,模拟人类视觉推理,取得较好效果!
【EMNLP2023】清华联合阿里提出了利用大型语言模型辅助多模态OOD检测的新方法!
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
实验室没有GPU也能做深度学习!这3种白嫖GPU算力的平台你一定要知道!
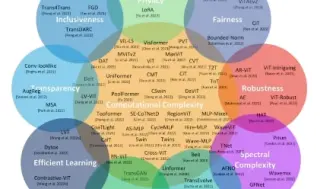
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
Google的神操作又来了!这次,拍了一支奥运主题的广告,结果引发了众怒。发布没几个小时,就被骂得关闭了评论区。广告让人们思考一个问题“AI的价值是什么?”技术
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
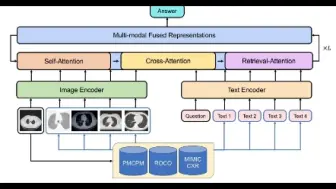
阿里联合清华提出了用于医学VQA的新方法RAMM,利用检索增强的策略在医学VQA数据集上取得新SOTA!数据集,代码即将开源!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
CVPR2023 基于掩码的视觉和语言Transformer,能够同时完成以文生图和Image Captioning两种多模态生成任务,且效果非常不错!
LLama3.1:Meta给了李彦宏一记耳光
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!