V
主页
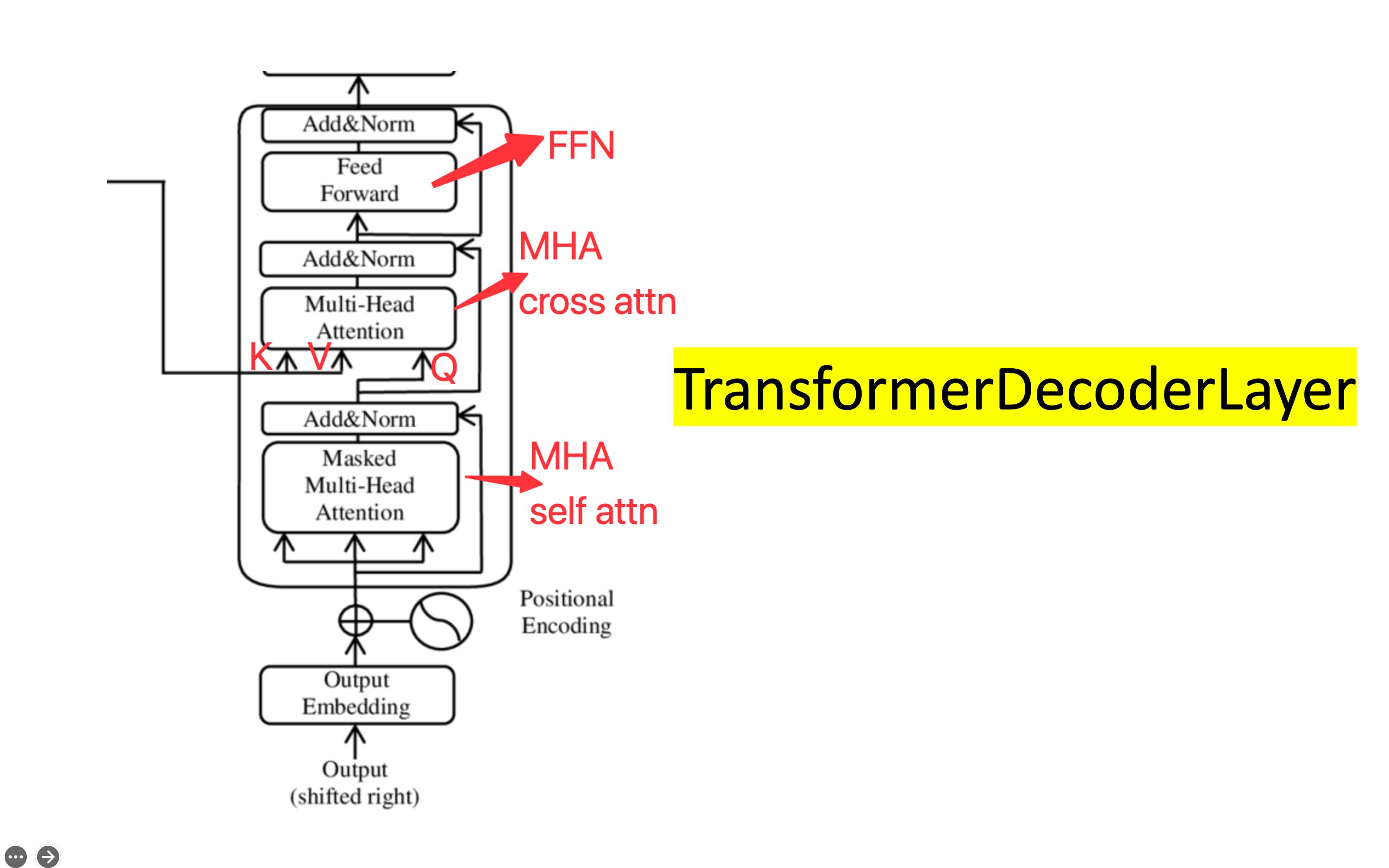
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/05_transformer_decoder_layer.ipynb transformer encoder layer: BV1XX4y1B71n
打开封面
下载高清视频
观看高清视频
视频下载器
都2024了,还不知道先学Transformer还是Diffusion?迪哥精讲BERT、Swin、DETR、VIT四大核心模型,原理讲解+论文解读+代码复现!
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[动手写神经网络] 手动实现 Transformer Encoder
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[性能测试] 03 单 4090 BERT、GPT2、T5 TFLOPS 测试及对比 3090TI
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
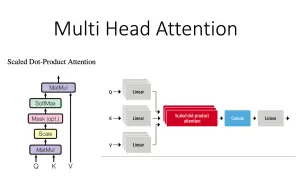
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
【全126集】目前B站最系统的Transformer教程!入门到进阶,全程干货讲解!拿走不谢!(神经网络/NLP/注意力机制/大模型/GPT/RNN)
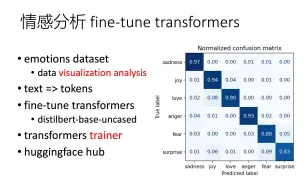
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节
不看太可惜!又快又准,即插即用!Sage Attention——清华8bit量化Attention
吹爆!不愧是中科院大佬,7天就把Transformer、RNN、BERT和迁移学习讲透了!整整100集付费,全程干货讲解,这还学不会up直接退出IT圈!
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
[动手写 Transformer] 从 RNN 到 Transformer,为什么需要位置编码(position encoding)
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
CoT不行?Long Context LLM的Hyper-Multi-Step
[调包侠] 使用 PyTorch Swin Transformer 完成图像分类
[动手写神经网络] 05 使用预训练 resnet18 提升 cifar10 分类准确率及误分类图像可视化分析
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
强推!这可能是B站最全的(Python+Transformer+大模型)系列课程了,堪称AI大模型系列课程的巅峰之作!-人工智能/提示词工程/RAG/大模型微调
[LLM && AIGC] 05 OpenAI 长文本(long text,超出 max_tokens)处理及 summary,划分 chunk 处理
剑指Softmax注意力梯度下降,基于指数变换的注意力实在厉害! 深度学习这下真大升级!
[AI硬件科普] 内存/显存带宽,从 NVIDIA 到苹果 M4
[损失函数设计] 为什么多分类问题损失函数用交叉熵损失,而不是 MSE
[pytorch] 激活函数,从 ReLU、LeakyRELU 到 GELU 及其梯度(gradient)(BertLayer,FFN,GELU)
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
[LangChain] 05 LangChain、LangGraph 结构化输出(Structured output),gpt-4o-2024-08-06
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
绝了!用降噪耳机原理升级注意力? 微软亚研&清华独创Transformer
[动手写 bert 系列] Bert 中的(add & norm)残差连接与残差模块(residual connections/residual blocks)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
3 GPT2模型实现、训练及推理
[动手写 bert 系列] 02 tokenizer encode_plus, token_type_ids(mlm,nsp)
[动手写神经网络] 如何设计卷积核(conv kernel)实现降2采样,以及初探vggnet/resnet 卷积设计思路(不断降空间尺度,升channel)