V
主页
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
发布人
本期 code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/03_transformer_architecture_multi_head_attention.ipynb 系列视频:https://space.bilibili.com/59807853/channel/collectiondetail?sid=496538
打开封面
下载高清视频
观看高清视频
视频下载器
多头注意力(Multi-Head Attention)
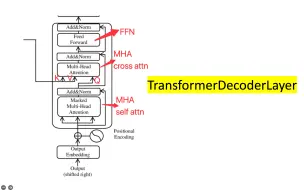
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
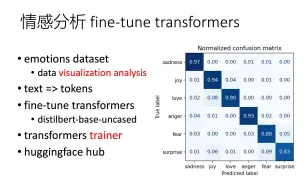
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
[性能测试] 03 单 4090 BERT、GPT2、T5 TFLOPS 测试及对比 3090TI
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[动手写神经网络] 手动实现 Transformer Encoder
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[LLMs inference] hf transformers 中的 KV cache
[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节
[personal chatgpt] Llama2 7B vs. Llama3 8B (词表、attention 及 mlp)
[LLMs 实践] 21 llama2 源码分析 GQA:Grouped Query Attention
[动手写 bert 系列] 解析 bertmodel 的output(last_hidden_state,pooler_output,hidden_state)
[BERT 番外] Sin Position Encoding 的简洁实现(RoPE 基础)
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
[动手写 bert 系列] 02 tokenizer encode_plus, token_type_ids(mlm,nsp)
[动手写Bert系列] bertencoder self attention 计算细节及计算过程
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[动手写 bert 系列] torch.no_grad() vs. param.requires_grad == False
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
[蒙特卡洛方法] 04 重要性采样补充,数学性质及 On-policy vs. Off-policy
[动手写bert] bert pooler output 与 bert head
[动手写 bert 系列] Bert 中的(add & norm)残差连接与残差模块(residual connections/residual blocks)
[工具的使用] python jupyter 环境安装配置拓展(nbextension)(ExcecuteTime:执行时间,Table of Content)
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
[强化学习基础 03] 多臂老虎机(Multi-Armed Bandit)与 UCB
[动手写 bert] masking 机制、bert head 与 BertForMaskedLM
[pytorch distributed] 01 nn.DataParallel 数据并行初步
[LLMs 实践] 04 PEFT/LoRA 源码分析