V
主页
[NeRF进展,3D分割] 上海交通大学、华中科技大学、华为提出SA3D,给定一个NeRF,SA3D可以完成目标物体的3D分割
发布人
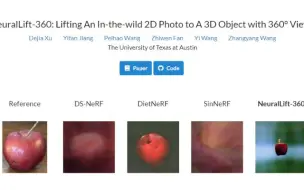
Segment Anything in 3D with NeRFs Jiazhong Cen(上海交通大学), Zanwei Zhou(上海交通大学), Jiemin Fang(华中科技大学), Wei Shen(上海交通大学), Lingxi Xie(华为), Xiaopeng Zhang(华为), Qi Tian(华为) 项目主页:https://jumpat.github.io/SA3D/ Github主页:https://github.com/Jumpat/SegmentAnythingin3D The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any object/part in various 2D images, yet its ability for 3D has not been fully explored. The real world is composed of numerous 3D scenes and objects. Due to the scarcity of accessible 3D data and high cost of its acquisition and annotation, lifting SAM to 3D is a challenging but valuable research avenue. With this in mind, we propose a novel framework to Segment Anything in 3D, named SA3D. Given a neural radiance field (NeRF) model, SA3D allows users to obtain the 3D segmentation result of any target object via only one-shot manual prompting in a single rendered view. With input prompts, SAM cuts out the target object from the according view. The obtained 2D segmentation mask is projected onto 3D mask grids via density-guided inverse rendering. 2D masks from other views are then rendered, which are mostly uncompleted but used as cross-view self-prompts to be fed into SAM again. Complete masks can be obtained and projected onto mask grids. This procedure is executed via an iterative manner while accurate 3D masks can be finally learned. SA3D can adapt to various radiance fields effectively without any additional redesigning. The entire segmentation process can be completed in approximately two minutes without any engineering optimization. Our experiments demonstrate the effectiveness of SA3D in different scenes, highlighting the potential of SAM in 3D scene perception. The project page is at https://jumpat.github.io/SA3D/.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF Relighting进展,SIGGRAPH] 浙大、微软亚研院等提出从一组物体的无结构图片,使用阴影和高光hints进行NeRF重光照的模型
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,物体相机] MIT与莱斯大学脑洞大开:ORCa,将有光泽的物体转为神经场相机,将反光的不可见场景建模,可以看到物体看到的而不是相机看到的场景
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,few-shot重建,群友工作] UCLA, nVidia提出FreeNeRF,一个关键观察触发了一个极简的优化,使少量视角重建效果大幅度提升
[NeRF进展,单视频大规模场景重建] KAIST,台大,Meta等发表Progressive LocalRF,使用单视频重建大规模场景NeRF,提升显著
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,渲染质量提升] Google NeRF的几位创始人:Zip-NeRF,解决Mip-NeRF 360锯齿问题,复杂场景渲染提升,训练速度提升22倍
[NeRF进展,编辑方向] 三星多伦多AI中心,多伦多大学,约克大学等:SPIn-NeRF,可快快速完成3D Segmentation和Inpainting任务
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,任意相机路径NeRF快速重建] 香港大学、南洋理工大学、马克斯普朗克等CVPR Highlight:F2NeRF,任意相机路径NeRF快速重建
[NeRF进展,单图实时3D画像] UCSD, nVidia,斯坦福提出LP3D,使用无姿态单图,实时推理和渲染真实感3D表达,合成高质量3D画像
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF进展,大型城市场景建模] 香港中文大学、浙江大学、马克斯普朗克等发布GridNeRF,高效建模大规模真实感城市3D场景
[动态NeRF进展]马里兰大学提出DMRF,一种在渲染和模拟中混合了Mesh和NeRF的方法,提出了光源、阴影和物理模拟的可实时交互方法,在网格插入取得良好效果
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
[NeRF进展,开源大规模场景] DNMP(同济、港中文、上海AI实验室,CPII),一种使用可变形神经mesh的,高质量快速的重建和渲染城市级别神经场的方法
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[NeRF编辑进展,开源] Seal-3D(浙江大学CS&AUS, CAD&CG实验室),一种可让用户自由在像素级别NeRF编辑的方法,并可实时预览编辑结果
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM