V
主页
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
发布人
SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction (CVPR 2023) Zhizhuo Zhou, Shubham Tulsiani (CMU) 项目主页:https://sparsefusion.github.io/ Github主页:https://github.com/zhizdev/sparsefusion We propose _SparseFusion_, a sparse view 3D reconstruction approach that unifies recent advances in neural rendering and probabilistic image generation.Existing approaches typically build on neural rendering with re-projected features but fail to generate unseen regions or handle uncertainty under large viewpoint changes. Alternate methods treat this as a (probabilistic) 2D synthesis task, and while they can generate plausible 2D images, they do not infer a consistent underlying 3D. However, we find that this trade-off between 3D consistency and probabilistic image generation does not need to exist. In fact, we show that geometric consistency and generative inference can be complementary in a mode seeking behavior.By distilling a 3D consistent scene representation from a view-conditioned latent diffusion model, we are able to recover a plausible 3D representation whose renderings are both accurate and realistic. We evaluate our approach across 51 categories in the CO3D dataset and show that it outperforms existing methods, in both distortion and perception metrics, for sparse view novel view synthesis.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[单图生成3D] UCSD, UCLA, 浙大, 康奈尔等:One-2-3-45,Zero123+SDF,超快速生成3D且几何一致性高,图片或文本生成高质量3D
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,大型城市场景建模] 香港中文大学、浙江大学、马克斯普朗克等发布GridNeRF,高效建模大规模真实感城市3D场景
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[三维重建] nVidia提出NKSR,一种新的从噪声的稀疏的点云重建地球级别3D表面的方法,可以在数秒中内完成对百万点的重建,并达到极好的效果
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[NeRF进展,单图实时3D画像] UCSD, nVidia,斯坦福提出LP3D,使用无姿态单图,实时推理和渲染真实感3D表达,合成高质量3D画像
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域
[NeRF进展,交互编辑方向] Inria, 马克斯普郞克学院提出NerfShop,使用基于Cage变形的方法进行物体的交互式选择与编辑,进一步推动实用
[NeRF+文本转3D] nVidia,多伦多大学Sanja团队:ATT3D,在一秒内使用文本生成3D的方法,极大提升了生成速度,并可完成简单的3D转换型动画
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[Diffusion进展,文本生成360度体验] Intel提出LDM3D,使用文本生成RGBD图,并将RGBD图渲染为360度三维体验感内容
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,任意相机路径NeRF快速重建] 香港大学、南洋理工大学、马克斯普朗克等CVPR Highlight:F2NeRF,任意相机路径NeRF快速重建
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[NeRF+自动驾驶] 浙大、图宾根大学提出PanopticNeRF360,将3D标记与带噪声的2D语义线索组合生成一致性全景标签和高质量任意视角图片的方法
[AIGC进展,使用多种因素合成,提升合成控制力] 阿里与蚂蚁金服提出Composer,使用多种因素训练diffusion model,提高合成的组合能力和可控
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[Diffusion+Transformer,人体动画进展] 阿里达摩院刚刚提出一个统一的预训练扩散模型MoFusion,用于人体动画合成 (arXiv)
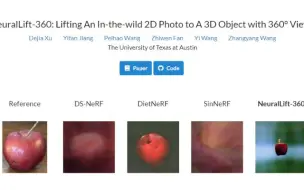
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF进展,物体相机] MIT与莱斯大学脑洞大开:ORCa,将有光泽的物体转为神经场相机,将反光的不可见场景建模,可以看到物体看到的而不是相机看到的场景
[NeRF进展,实时流建模] 斯坦福大学提出NeRFBridge,将机器人操作系统ROS与nerfstudio桥接,实时在线流式训练NeRF模型
2024最好出论文的两个研究方向:Diffusion扩散模型+对比学习,源码复现+模型精讲+论文解读,迪哥带你轻松搞定论文创新点!(研一研二必看)
[NeRF进展,单视频大规模场景重建] KAIST,台大,Meta等发表Progressive LocalRF,使用单视频重建大规模场景NeRF,提升显著