V
主页
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
发布人
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior Junshu Tang(上海交通大学), Tengfei Wang(香港科技大学), Bo Zhang(微软研究院), Ting Zhang(微软研究院), Ran Yi(上海交通大学), Lizhuang Ma(上海交通大学), Dong Chen(微软研究院) 项目主页:https://make-it-3d.github.io/ Github主页:https://github.com/junshutang/Make-It-3D In this work, we investigate the problem of creating high-fidelity 3D content from only a single image. This is inherently challenging: it essentially involves estimating the underlying 3D geometry while simultaneously hallucinating unseen textures. To address this challenge, we leverage prior knowledge from a well-trained 2D diffusion model to act as 3D-aware supervision for 3D creation. Our approach, Make-It-3D, employs a two-stage optimization pipeline: the first stage optimizes a neural radiance field by incorporating constraints from the reference image at the frontal view and diffusion prior at novel views; the second stage transforms the coarse model into textured point clouds and further elevates the realism with diffusion prior while leveraging the high-quality textures from the reference image. Extensive experiments demonstrate that our method outperforms prior works by a large margin, resulting in faithful reconstructions and impressive visual quality. Our method presents the first attempt to achieve high-quality 3D creation from a single image for general objects and enables various applications such as text-to-3D creation and texture editing.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM
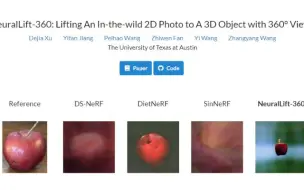
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,few-shot重建,群友工作] UCLA, nVidia提出FreeNeRF,一个关键观察触发了一个极简的优化,使少量视角重建效果大幅度提升
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[Diffusion进展,文本转视频]新加坡国立大学、腾讯ARC实验室提出Tune-A-Video,使用文本生成图片模型One-Shot精调至视频,效果很棒
[3D数据集,超百万文本标注3D数据集] Objaverse公开发布,近百万文本详细标注的3D数据集可下载,已有数个关联的文本生成3D论文发表,值得关注和实验
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[单视图重建]ETH、Google和TUM提出KYN,一种基于NeRF的3D密度重建方法,使用单视图恢复3D形状,提升了零样本泛化能力
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[Diffusion+Transformer,人体动画进展] 阿里达摩院刚刚提出一个统一的预训练扩散模型MoFusion,用于人体动画合成 (arXiv)
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[3D生成] 浙大、字节SIG 24工作Coin3D,使用粗糙模型三维控制,可控且交互地生成三维资产,提升导出带纹理网格的质量
[NeRF进展,反射折射物体表达] 南开大学提出MS-NeRF,一种针对场景中反射和折射物体表达和渲染的方法,低消耗地提升NeRF模型,对相应场景效果提升显著
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域
[NeRF进展] 多伦多大学,SFU,Google和Adobe提出Bayers' Rays,在预训练的NeRF里预测不确定性,清除由不完整或遮挡造成的重建缺陷
[NeRF进展,体渲染几何优化] UCSD,Adobe, ETH,蒂宾根大学提出NeuManifold,结合体渲染与流形生成精确网格的高速渲染,与传统管线兼容
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[NeRF纹理生成,SIGGRAPH] 中科院,腾讯等提出NeRF-Texture,从多视角图像采集和生成纹理,可应对如草、叶子、纺织品等3D空间复杂纹理生成
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[三维重建] nVidia提出NKSR,一种新的从噪声的稀疏的点云重建地球级别3D表面的方法,可以在数秒中内完成对百万点的重建,并达到极好的效果
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果