V
主页
[Mesh进展] nVidia,多伦多大学提出FlexiCubes,使用isosurface或标量场迭代优化3D表面Mesh,相比MC和DMTeT取得巨大提升
发布人
Flexible Isosurface Extraction for Gradient-Based Mesh Optimization Tianchang Shen, Jacob Munkberg, Jon Hasselgren, Kangxue Yin, Zian Wang, Wenzheng Chen, Zan Gojcic, Sanja Fidler, Nicholas Sharp, Jun Gao nVidia, 多伦多大学,Vector Institute This work considers gradient-based mesh optimization, where we iteratively optimize for a 3D surface mesh by representing it as the isosurface of a scalar field, an increasingly common paradigm in applications including photogrammetry, generative modeling, and inverse physics. Existing implementations adapt classic isosurface extraction algorithms like Marching Cubes or Dual Contouring; these techniques were designed to extract meshes from fixed, known fields, and in the optimization setting they lack the degrees of freedom to represent high-quality feature-preserving meshes, or suffer from numerical instabilities. We introduce **FlexiCubes**, an isosurface representation specifically designed for optimizing an unknown mesh with respect to geometric, visual, or even physical objectives. Our main insight is to introduce additional carefully-chosen parameters into the representation, which allow local flexible adjustments to the extracted mesh geometry and connectivity. These parameters are updated along with the underlying scalar field via automatic differentiation when optimizing for a downstream task. We base our extraction scheme on Dual Marching Cubes for improved topological properties, and present extensions to optionally generate tetrahedral and hierarchically-adaptive meshes. Extensive experiments validate **FlexiCubes** on both synthetic benchmarks and real-world applications, showing that it offers significant improvements in mesh quality and geometric fidelity.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[AIGC进展,文本到3D Mesh] nVidia在CVPR 23年的Highlight工作Magic3D,选择使用Mesh进行扩散,生成高清晰度Mesh
[自动建模,动态3D衣服] 香港中文大学(深圳)、腾讯提出REC-MV,联合优化衣服特征曲线和SDF,提取时域连贯mesh,生成高质量3D衣服动态效果,开源
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[AIGC进展,使用shape+文本生成纹理] 特拉维夫大学提出TEXTure,通在已知3D shape情况下,使用文本可生成、编辑和迁移纹理效果
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[AIGC进展,使用多种因素合成,提升合成控制力] 阿里与蚂蚁金服提出Composer,使用多种因素训练diffusion model,提高合成的组合能力和可控
[NeRF进展,时间一致动态场景重建] MPI, Meta提出SceNeRFlow,一种通用的,非刚性场景的,时间一致性的NeRF重建方法,可重建大尺度运动
[NeRF进展] 浙江大学、阿里提出Mirror-NeRF,可以学习镜子准确的几何和反射效果,并可以支持多种不同的场景操控应用,如在场景中添加物体或镜子等
[NeRF进展,渲染质量提升] Google NeRF的几位创始人:Zip-NeRF,解决Mip-NeRF 360锯齿问题,复杂场景渲染提升,训练速度提升22倍
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[3DGS进展] 浙大CADCG,字节提出可变形的3DGS方法,对单目动态场景进行建模,在渲染质量和速度取得优势,适合NVS问题,时间序列合成和实时渲染
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
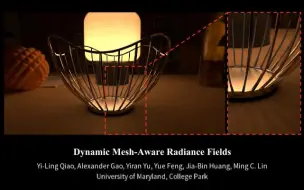
[动态NeRF进展]马里兰大学提出DMRF,一种在渲染和模拟中混合了Mesh和NeRF的方法,提出了光源、阴影和物理模拟的可实时交互方法,在网格插入取得良好效果
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[3D人脸采集,偏振光重建方向] 慕尼黑工业大学、Meta,Matthias大神、Justus提出PolFace,使用偏振光在手机上即可采集出高质量3D人脸效果
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频
[NeRF进展,大规模城市场景建模] CMU, Argo AI提出SUDS,构建最大的动态NeRF,可快速重建大规模城市场景,并因分支建模,支持一定后期处理能力
[NeRF进展] 多伦多大学,SFU,Google和Adobe提出Bayers' Rays,在预训练的NeRF里预测不确定性,清除由不完整或遮挡造成的重建缺陷
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[NeRF进展] nVidia,多伦多大学提出Adaptive Shell的高效NeRF渲染方法,在体渲染和表面渲染方法之间平滑切换,可以高质量高速渲染NeRF