V
主页
[NeRF进展,few-shot重建,群友工作] UCLA, nVidia提出FreeNeRF,一个关键观察触发了一个极简的优化,使少量视角重建效果大幅度提升
发布人
FreeNeRF: Improving Few-shot Neural Rendering with Free Frequency Regularization Jiawei Yang(UCLA), Marco Pavone(nVidia Research, Stanford), Yue Wang (nVidia Research) 项目主页:https://jiawei-yang.github.io/FreeNeRF/ Github主页:https://github.com/Jiawei-Yang/FreeNeRF Novel view synthesis with sparse inputs is a challenging problem for neural radiance fields (NeRF). Recent efforts alleviate this challenge by introducing external supervision, such as pre-trained models and extra depth signals, or by using non-trivial patch-based rendering. In this paper, we present Frequency regularized NeRF (FreeNeRF), a surprisingly simple baseline that outperforms previous methods with minimal modifications to plain NeRF. We analyze the key challenges in few-shot neural rendering and find that frequency plays an important role in NeRF’s training. Based on this analysis, we propose two regularization terms: one to regularize the frequency range of NeRF’s inputs, and the other to penalize the near-camera density fields. Both techniques are “free lunches” that come at no additional computational cost. We demonstrate that even with just one line of code change, the original NeRF can achieve similar performance to other complicated methods in the few-shot setting. FreeNeRF achieves state-of-theart performance across diverse datasets, including Blender, DTU, and LLFF. We hope that this simple baseline will motivate a rethinking of the fundamental role of frequency in NeRF’s training, under both the low-data regime and beyond. This project is released at FreeNeRF.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,大规模城市场景建模] CMU, Argo AI提出SUDS,构建最大的动态NeRF,可快速重建大规模城市场景,并因分支建模,支持一定后期处理能力
[三维重建] nVidia提出NKSR,一种新的从噪声的稀疏的点云重建地球级别3D表面的方法,可以在数秒中内完成对百万点的重建,并达到极好的效果
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
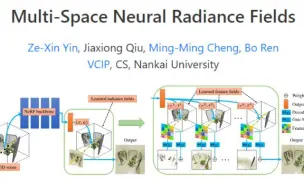
[NeRF进展,反射折射物体表达] 南开大学提出MS-NeRF,一种针对场景中反射和折射物体表达和渲染的方法,低消耗地提升NeRF模型,对相应场景效果提升显著
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[3D人脸采集,偏振光重建方向] 慕尼黑工业大学、Meta,Matthias大神、Justus提出PolFace,使用偏振光在手机上即可采集出高质量3D人脸效果
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
[AIGC进展,文本生成3D模型方向] 华南理工大学提出Fantasia3D,将几何和外观学习进行分离,在转化过程中考虑空域变换的BRDF,提升真实感
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[NeRF产品应用] 开源的NerfStudio(目前Github star 2600)使用不同设备采集后重建、渲染效果
[点云+神经渲染进展] Apple, CMU, UBC提出Pointersect,给定一个点云,在不转换为其他表达的情况下,进行推理光线与表面相交性
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[3DGan进展] nVidia, UCSD提出新的3D GAN方法,无监督地将神经体积渲染缩放到原始2D图像的更高分辨率,生成超细粒度3D几何效果
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
SIGGRAPH 2024 最佳论文荣誉提名!港中文提出:双边引导辐射场处理技术!3D重建新突破!
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF