V
主页
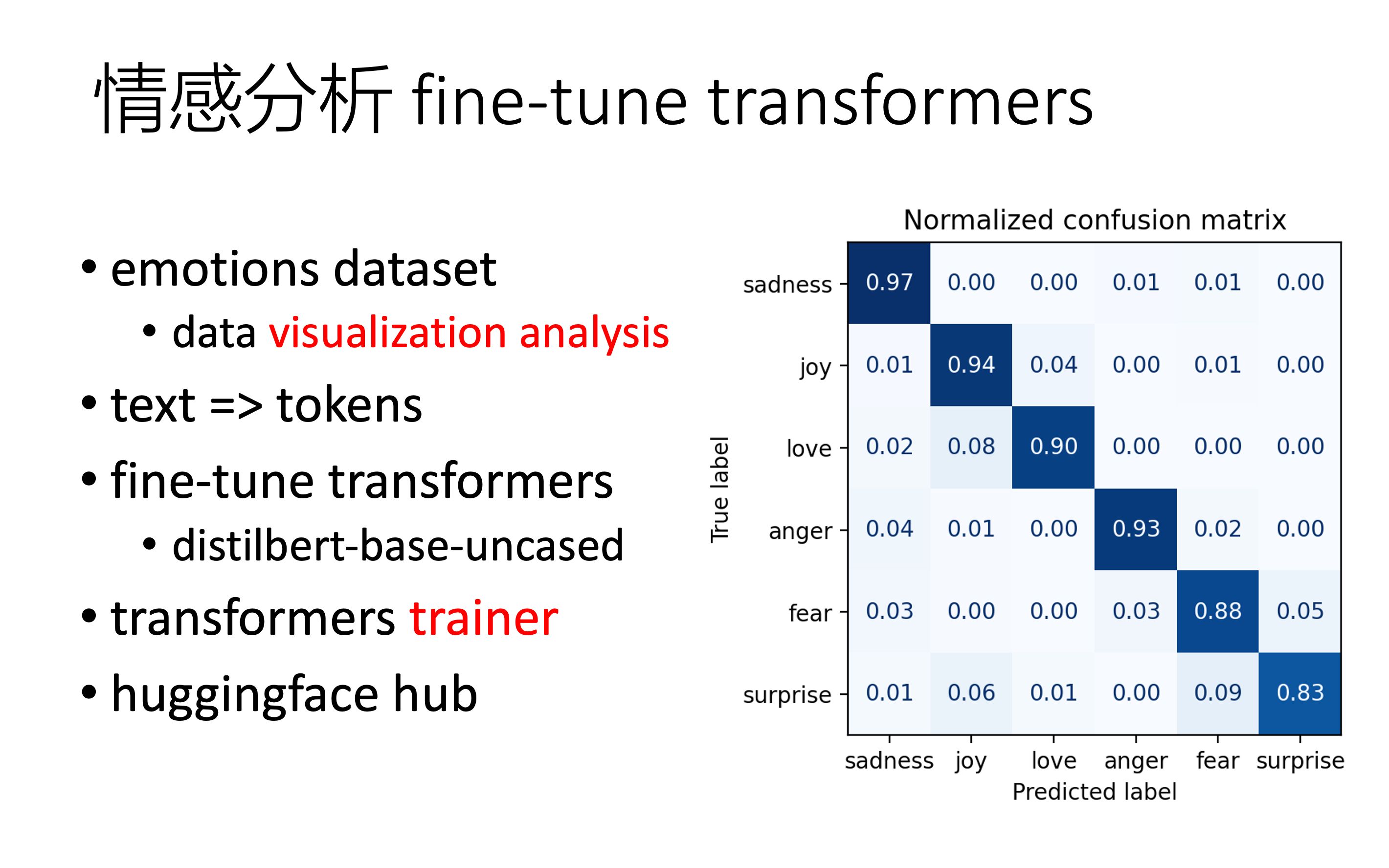
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
发布人
本期 code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/01_fine_tune_transformers_on_classification.ipynb 系列视频:https://space.bilibili.com/59807853/channel/collectiondetail?sid=496538
打开封面
下载高清视频
观看高清视频
视频下载器
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
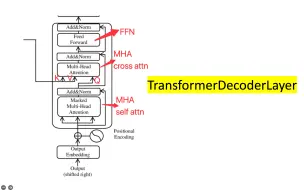
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
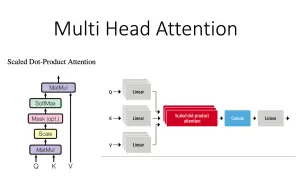
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
【墙裂推荐!】Hugging Face 模型微调训练-基于BERT的中文评价情感分析
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[动手写 bert 系列] bert model architecture 模型架构初探(embedding + encoder + pooler)
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[sbert 01] sentence-transformers pipeline
基于【LSTM文本分类项目实战】基于LSTM长短期记忆模型实现文本分类,原理详解+代码复现!(人工智能、深度学习、神经网络、计算机视觉、AI、Pytorch)
[性能测试] 03 单 4090 BERT、GPT2、T5 TFLOPS 测试及对比 3090TI
[动手写神经网络] 02 逐行写代码 CNN pipeline 图像分类(模型结构、训练、评估)
[LLMs 实践] 04 PEFT/LoRA 源码分析
[LLMs 实践] 14 llama2 introduction 及 fine tune llama2(guanaco dataset)
[python nlp] 01 词频分析与 Zipf law 齐夫定律(log-log plot)
[动手写 bert 系列] 解析 bertmodel 的output(last_hidden_state,pooler_output,hidden_state)
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[BERT 番外] Sin Position Encoding 的简洁实现(RoPE 基础)
实战练手!基于PyTorch与RNN实现的LSTM文本分类任务实战教程,全程通俗易懂!
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
[LLM & AIGC] 03 openai embedding (text-embedding-ada-002)基于 embedding 的文本语义匹配
[动手写 bert 系列] 02 tokenizer encode_plus, token_type_ids(mlm,nsp)
[动手写 bert] masking 机制、bert head 与 BertForMaskedLM
[动手写bert] bert pooler output 与 bert head
[AI 核心概念及计算] 概率计算 01 pytorch 最大似然估计(MLE)伯努利分布的参数
[五分钟系列] 01 gensim embedding vectors 距离及可视化分析
[动手写 bert 系列] bert embedding 源码解析,word_embedding/position_embedding/token_type
12小时搞懂TensorFlow深度学习框架,从安装到实操零基础教学!—猫狗识别、文本分类、时间序列预测、迁移学
[动手写 bert 系列] BertTokenizer subword,wordpiece 如何处理海量数字等长尾单词
[纳什荐书][生成式AI] 01 《GPT图解》导读
[动手写神经网络] 05 使用预训练 resnet18 提升 cifar10 分类准确率及误分类图像可视化分析
[动手写Bert系列] bertencoder self attention 计算细节及计算过程