V
主页
国科大联合华为提出金字塔结构的特征MIM预训练方法,性能大幅超越MAE等视觉掩码自监督方法!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
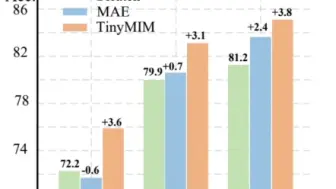
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
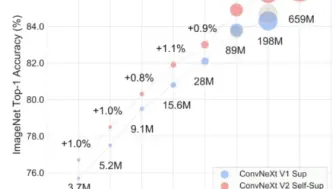
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
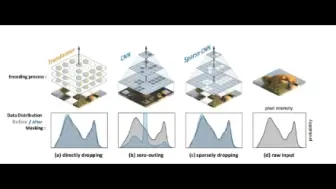
字节联合北大提出新的用于卷积网络的掩码自监督预训练方案Spark,性能超越ConvNext V2!代码和模型目前已开源!
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
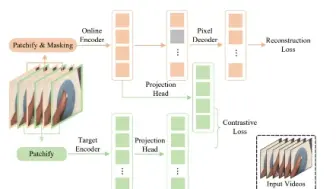
字节联合南开大学提出了用于视频动作识别的自监督框架CMAE-V,融合了MAE和对比学习,在视频动作识别任务取得SOTA!
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
微软提出了新的模型蒸馏策略G2SD,利用掩码自动编码器结合特征蒸馏和KD蒸馏,学生模型的精度达到教师模型的98%!目前已开源!
字节联合爱丁堡大学提出新的视觉预训练方法MUG,取得新的SOTA!模型和代码均已开源,快来领取!
DeepMind提出了新的半监督学习方法SEMPPL,结合当前的对比学习自监督学习方案,表征能力得到进一步提升!
性能翻倍!LSTM+Transformer王炸创新,荣登Nature,精度高达95.56%!!整理11种融合创新方案!机器学习|深度学习|计算机视觉
【保姆级教程】6小时掌握开源大模型本地部署到微调,从硬件指南到ChatGLM3-6B模型部署微调实战,这应该是B站最好的大模型教程了!
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
苹果公司学者提出最快的ViT结构FastViT,实现了效率和精度的trade-off。比Efficient 快5倍,比ConvNext快2倍!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
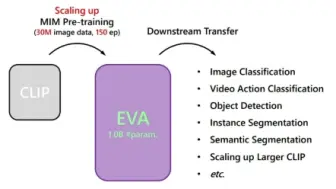
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
阿里提出了一种联合多个语义分割数据集进行训练的语义分割方法LMSeg,相比单一数据集训练提升明显!
腾讯联合浙大提出新的视觉Transformer网络CrossFormer,参数量更少同时性能超过Swin!目前已开源!
微软多模态团队提出了新的语言增强多模态预训练大模型,可以类似BLIP2进行多模态chat,效果很惊艳!
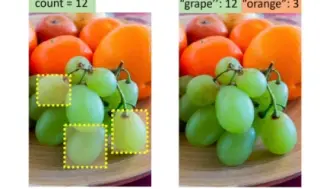
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
Self-Attenion的重思考,VIT更快的同时性能更强,Skip Attention通过减少注意力来提升VIT性能!
帝国理工学院发布! 适应新型抓取的技能:一种自监督的方法!
Transformer技术原理,论文讲解!带你秒懂Transformer底层逻辑原理!真的通俗易懂!(人工智能、深度学习、机器学习算法、神经网络、AI)
商汤科技提出具有双层路由注意力的视觉Transformer,减少原始ViT计算量的同时性能大幅超过Swin Transformer!已被CVPR 2023接收!
神马!只用60行Numpy代码手搓出GPT大模型!这老哥简直太牛啦
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
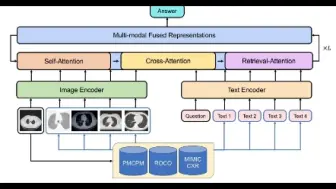
阿里联合清华提出了用于医学VQA的新方法RAMM,利用检索增强的策略在医学VQA数据集上取得新SOTA!数据集,代码即将开源!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
【YOLOv10】12分钟通关YOLOv10,环境搭建、模型训练、验证推理、导出、数据集
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
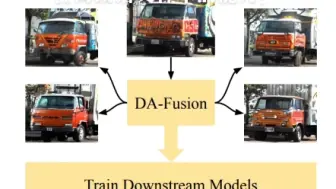
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
Nvidia联合Meta AI提出了基于Transformer的强大实例Mask生成框架MAL,仅使用Box标注即能达到接近Mask监督的效果!
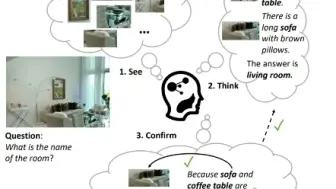
MIT联合清华提出基于知识的视觉推理多模态模型IPVR,模拟人类视觉推理,取得较好效果!
还得看吴恩达!一口气讲透CNN、RNN、GAN、LSTM、YOLO、transformer等六大深度学习神经网路算法!真的不要太爽~(AI人工智能丨机器学习)
CVPR2023 基于掩码的视觉和语言Transformer,能够同时完成以文生图和Image Captioning两种多模态生成任务,且效果非常不错!
华五毕业,ai工程师,重度焦虑抑郁,每天都有濒死感,谈谈我的职场经历。不是我不想努力
上海AI Lab提出利用多种预训练模型进行集成学习的新方法CaFo,利用 GPT-3,CLIP,DINO等多种基础预训练模型提升少样本学习能力!
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!