V
主页
[动手写 bert 系列] bert model architecture 模型架构初探(embedding + encoder + pooler)
发布人
https://github.com/chunhuizhang/bilibili_vlogs/tree/master/fine_tune/bert/tutorials
打开封面
下载高清视频
观看高清视频
视频下载器
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[动手写神经网络] 手动实现 Transformer Encoder
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[动手写Bert系列] bertencoder self attention 计算细节及计算过程
[动手写 bert 系列] 解析 bertmodel 的output(last_hidden_state,pooler_output,hidden_state)
[动手写 bert 系列] bert embedding 源码解析,word_embedding/position_embedding/token_type
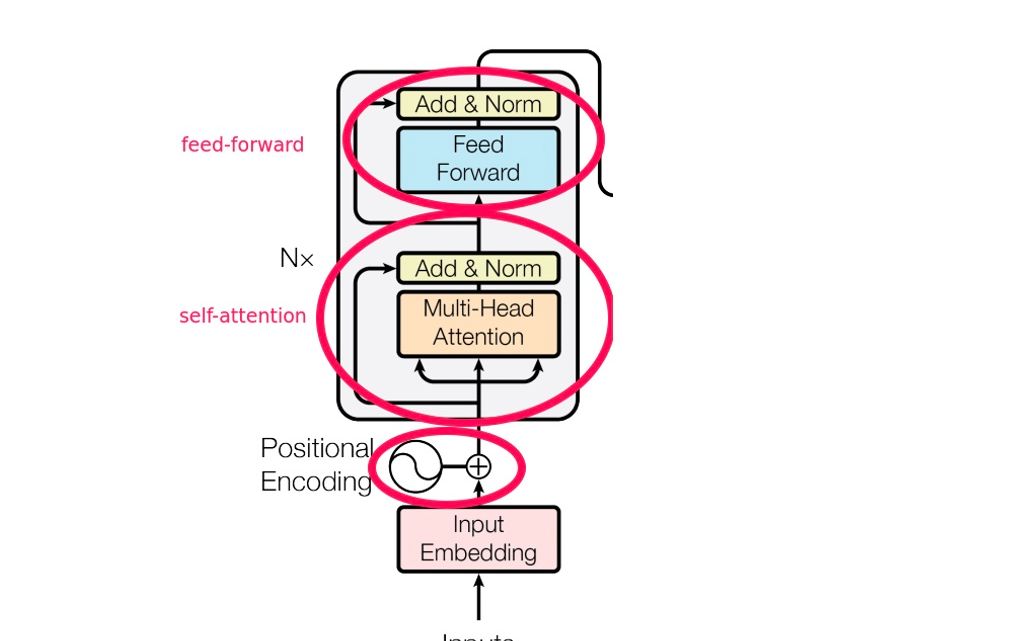
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
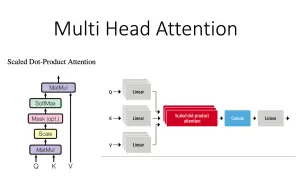
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
[调包侠] tencent ailab 中文语料 embedding vector(word2vec)
[动手写bert] bert pooler output 与 bert head
[模型拓扑结构] pytorch 注册钩子函数(register_forward_hook)实现对各个层(layer)输入输出 shape 的查看
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
[动手写 bert 系列] Bert 中的(add & norm)残差连接与残差模块(residual connections/residual blocks)
[pytorch 网络模型结构] 深入理解 nn.BatchNorm1d/2d 计算过程
4 BERT模型训练1-数据处理(构建mask 训练语料)
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
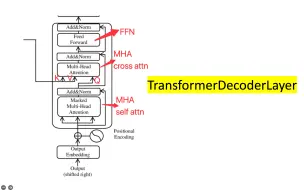
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[LLM+RL] 合成数据与model collapse,nature 正刊封面
[pytorch distributed] 04 模型并行(model parallel)on ResNet50
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[动手写 bert 系列] 02 tokenizer encode_plus, token_type_ids(mlm,nsp)
[动手写 bert 系列] BertTokenizer subword,wordpiece 如何处理海量数字等长尾单词
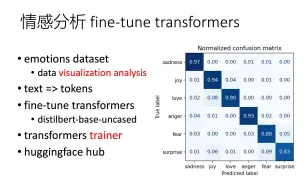
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[personal chatgpt] trl 基础介绍:reward model,ppotrainer
[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[动手写神经网络] 如何设计卷积核(conv kernel)实现降2采样,以及初探vggnet/resnet 卷积设计思路(不断降空间尺度,升channel)
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[Python 机器学习] 深入理解 numpy(ndarray)的 axis(轴/维度)
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[pytorch] nn.Embedding 前向查表索引过程与 one hot 关系及 max_norm 的作用
[pytorch] [求导练习] 05 计算图(computation graph)构建细节之 inplace operation(data与detach)
[五分钟系列] 01 gensim embedding vectors 距离及可视化分析
[动手写 bert 系列] torch.no_grad() vs. param.requires_grad == False
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[全栈深度学习] 01 docker 工具的基本使用及 nvidia cuda pytorch 镜像
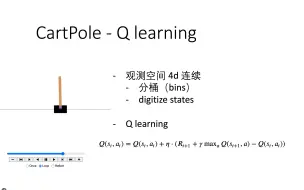
[pytorch 强化学习] 09 (逐行写代码)CartPole Q learning 基于连续状态离散化(digitize 分桶)
[pytorch 网络拓扑结构] 深入理解 nn.LayerNorm 的计算过程
[AI Agent] llama_index RAG 原理及源码分析