V
主页
[NeRF,场景语义建模与应用]Meta提出SSDNeRF,首个通用NeRF场景语义分割方法,将场景按语议分割建模,让NeRF二次编辑、丰富动画场景变为可能
发布人
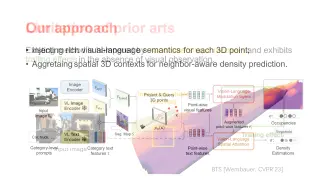
SSDNeRF: Semantic Soft Decomposition of Neural Radiance Fields Siddhant Ranade(University of Utah, Meta), Christoph Lassner, Kai Li, Christian Haene, Shen-Chi Chen, Jean-Charles Bazin, Sofien Bouaziz(Meta) 论文地址:https://arxiv.org/abs/2212.03406 NeRF通过场景的全景函数来将一个完整的场景参数化为一个辐射场。这是通过使用MLP与向高维空间的映射实现的。而且已经被证明可以得到非常细节粒度的场景信息。自然的,一样的参数化方法可以用来编码场景其他的属性,而不只它的辐射场。一个特别有趣的属性是场景的语义分解信息。我们提出了一种新的NeRF的语义软分解方法,称之为SSDNeRF,它可以合并编码场景信号本身和他们的语义信号。我们的方法将场景软分割为不同的语义组成部分,让我们可以正确的编码多个同向混合的语义类 -- 这也是其他现有方法无法达到的部分。这样做不仅可以生成一个详细的,三维的场景语义表达,也可以显示出MLP的规则化效果,从而帮助提升语义表达能力。我们在常见物体的数据集上展示了当前最佳的分割和重建效果,并展示了这个方法可以对一组随意拍摄的自拍视频中进行高质量、时序一致的视频编码和重新合成效果。 Neural Radiance Fields (NeRFs) encode the radiance in a scene parameterized by the scene's plenoptic function. This is achieved by using an MLP together with a mapping to a higher-dimensional space, and has been proven to capture scenes with a great level of detail. Naturally, the same parameterization can be used to encode additional properties of the scene, beyond just its radiance. A particularly interesting property in this regard is the semantic decomposition of the scene. We introduce a novel technique for semantic soft decomposition of neural radiance fields (named SSDNeRF) which jointly encodes semantic signals in combination with radiance signals of a scene. Our approach provides a soft decomposition of the scene into semantic parts, enabling us to correctly encode multiple semantic classes blending along the same direction -- an impossible feat for existing methods. Not only does this lead to a detailed, 3D semantic representation of the scene, but we also show that the regularizing effects of the MLP used for encoding help to improve the semantic representation. We show state-of-the-art segmentation and reconstruction results on a dataset of common objects and demonstrate how the proposed approach can be applied for high quality temporally consistent video editing and re-compositing on a dataset of casually captured selfie videos.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[单视图重建]ETH、Google和TUM提出KYN,一种基于NeRF的3D密度重建方法,使用单视图恢复3D形状,提升了零样本泛化能力
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
老鹿学Ai绘画:ControlNet对象类控制及语义颜色对照表制作方法
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,时间一致动态场景重建] MPI, Meta提出SceNeRFlow,一种通用的,非刚性场景的,时间一致性的NeRF重建方法,可重建大尺度运动
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
图像反推语义分割文字识别一个模型全搞定,Florence2微软多任务视觉模型,轻量王者
SyncTalk三种训练方式ave、deepspeech、hubert效果对比其中hubert防抖效果最好
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展,场景天气风格化渲染]UIUC、浙江大学,马里兰大学提出ClimateNeRF,在NeRF场景中融合天气物理渲染,实现真实感天气场景渲染效果
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,效果提升] TUM与Meta推出GANeRF,使用GAN来解决视角观察缺陷以及小的光照变化带来的重建质量不佳问题,提升1.4dB以上
GPT-5 将让 GPT-4o看起来像是一个小孩的玩具(人工智能大模型技术)!
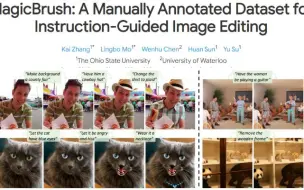
[数据集] 俄亥俄州立大学、滑铁卢大学:MagicBrush,一个人工标记的数据集,用来训练文本驱动的图片编辑,并精调instructPix2Pix验证了效果
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
SyncTalk第五讲以deepspeech方式训练解决双下巴问题并新增NPY文件生成工具
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[NeRF进展,语义驱动编辑] 浙江大学3DV国家重点实验室联合Google提出SINE,通过语义驱动NeRF编辑,完成多视角高质量、一致性的编辑操作
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[基础开源框架,实体分割工具箱]浙江大学Wentong Li开源BoxInstSeg,提供4种box-supervised实体分割算法(包括当前SOTA方法)
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
[NeRF机器人] 斯坦福报告:Perception-Rich Robot Autonomy with Neural Environment Models
遥感图像语义分割新前景:即插即用解码器设计,金字塔特征融合Mamba
[3D表达进展]密西根大学提出Neural Shape Compiler,可以实现文本、点云和程序间统一的转换框架,在多种3D表达任务中达到提升
[NeRF+Diffusion进展] nVidia,多伦多大学等推出NeuralField-LDM,使用神经场和生成模型解决复杂开放世界3D场景的建模和编辑能力
[神经材质压缩] nVidia杀疯了,提出NTC,使用神经压缩算法压缩纹理压缩,在增加了两层LOD后,不需要熵编码的情况下低码率压缩,解码只增加毫秒级消耗
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF 3D场景理解] UC伯克利、Luma AI提出GARField,使用辐射场对任何事物进行分组,从姿势图像输入分解为具有语义意义的组的层次结构的方法