V
主页
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/07_gpt2_decoding(generation).ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
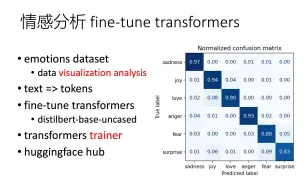
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
[GPT 番外] tied/share tensors wte与lm_head(GPT2LMHeadModel)
[gpt2 番外] training vs. inference(generate),PPL 计算,交叉熵损失与 ignore_index
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
[bert、t5、gpt] 04 构建 TransformerEncoderLayer(FFN 与 Layer Norm、skip connection)
[Python 机器学习] 深入理解 numpy(ndarray)的 axis(轴/维度)
[mcts] 02 mcts from scartch(UCTNode,uct_search, pUCT,树的可视化)
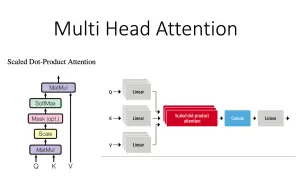
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[LLMs 实践] 07 fp16 与自动混合精度训练(amp)显著提升 batch size
[personal chatgpt] gpt-4o tokenizer 及特殊中文tokens(压缩词表),o200k_base
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
[LLM 番外] 自回归语言模型cross entropy loss,及 PPL 评估
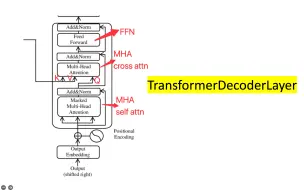
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[generative models] 概率建模视角下的现代生成模型(生成式 vs. 判别式,采样与密度估计)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[BERT 番外] Sin Position Encoding 的简洁实现(RoPE 基础)
[personal chatgpt] 从 RoPE 到 CoPE(绝对位置编码,相对位置编码,Contextual Position Encoding)
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
[LLMs 实践] 04 PEFT/LoRA 源码分析
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[动手写 bert 系列] bert embedding 源码解析,word_embedding/position_embedding/token_type
[动手写 bert 系列] 解析 bertmodel 的output(last_hidden_state,pooler_output,hidden_state)
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[prompt engineering] 从 CoT 到 ToT(Tree of Thoughts)
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
[动手写神经网络] 05 使用预训练 resnet18 提升 cifar10 分类准确率及误分类图像可视化分析
[动手写 bert 系列] torch.no_grad() vs. param.requires_grad == False
[LLMs 实践] 09 BPE gpt2 tokenizer 与 train tokenizer
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
[动手写bert] bert pooler output 与 bert head
[LLM && AIGC] 05 OpenAI 长文本(long text,超出 max_tokens)处理及 summary,划分 chunk 处理
[personal chatgpt] trl 基础介绍:reward model,ppotrainer