V
主页
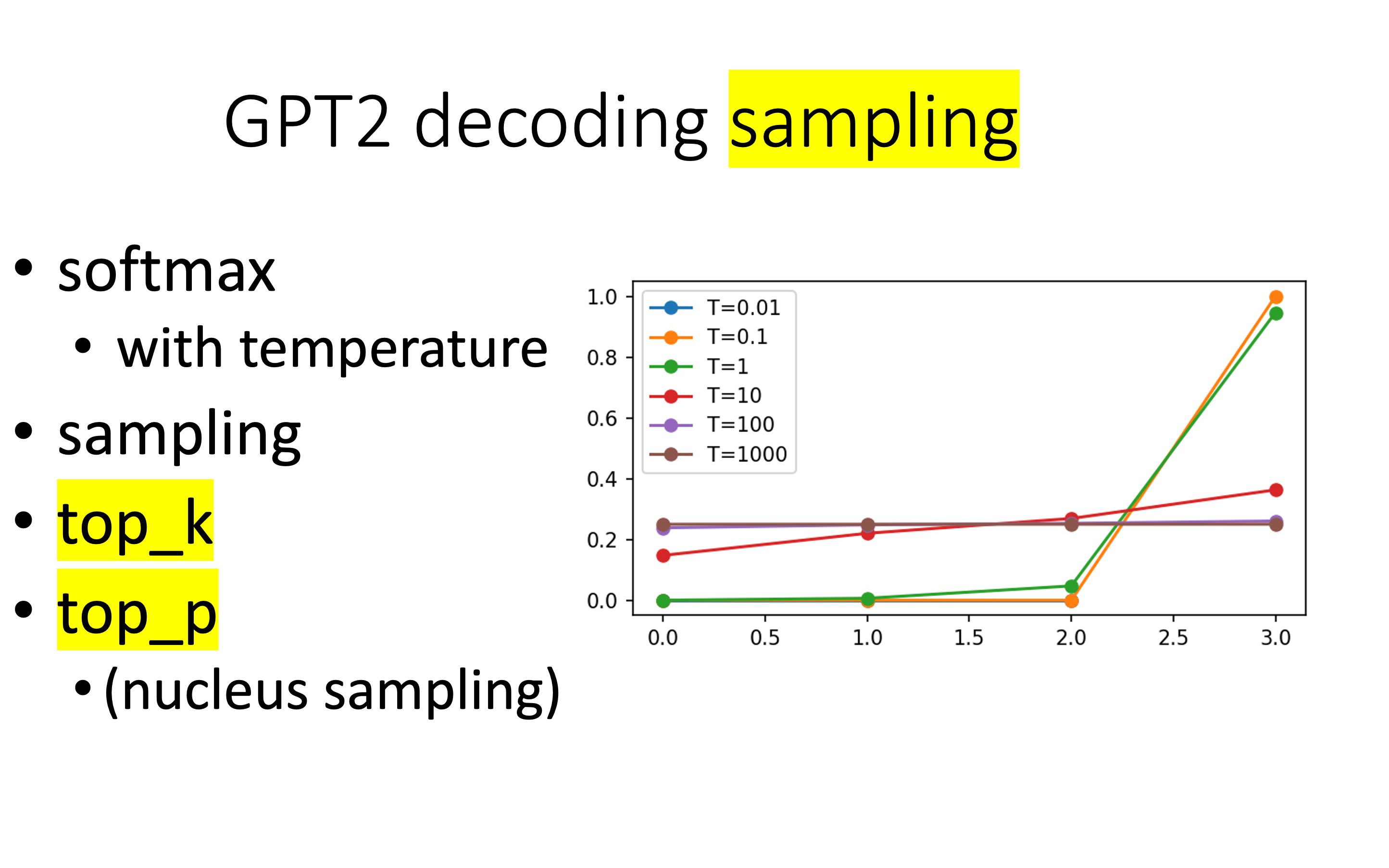
[bert、t5、gpt] 08 GPT2 sampling (top-k,top-p (nucleus sampling))
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/08_gpt2_decoding_sampling.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[bert、t5、gpt] 01 fine tune transformers 文本分类/情感分析
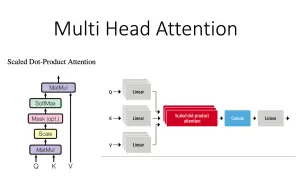
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[bert、t5、gpt] 06 GPT2 整体介绍(tokenizer,model forward)
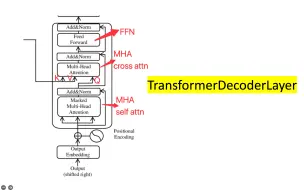
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[bert、t5、gpt] 09 T5 整体介绍(t5-11b,T5ForConditionalGeneration)
[bert、t5、gpt] 10 知识蒸馏(knowledge distill)初步,模型结构及损失函数设计
[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节
[LLM 番外] 自回归语言模型cross entropy loss,及 PPL 评估
[LLMs 实践] 09 BPE gpt2 tokenizer 与 train tokenizer
[personal chatgpt] peft LoRA merge pipeline(lora inject,svd)
[gpt2 番外] training vs. inference(generate),PPL 计算,交叉熵损失与 ignore_index
[性能测试] 03 单 4090 BERT、GPT2、T5 TFLOPS 测试及对比 3090TI
[性能测试] 04 双4090 BERT、GPT性能测试(megatron-lm、apex、deepspeed)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[GPT 番外] tied/share tensors wte与lm_head(GPT2LMHeadModel)
[动手写 bert 系列] bert embedding 源码解析,word_embedding/position_embedding/token_type
[LangChain] 03 LangGraph 基本概念(AgentState、StateGraph,nodes,edges)
[pytorch] 激活函数,从 ReLU、LeakyRELU 到 GELU 及其梯度(gradient)(BertLayer,FFN,GELU)
[全栈深度学习] 02 vscode remote(远程)gpus 服务器开发调试 debugger(以 nanoGPT 为例)
[animation & rendering] matplotlib funcanimation 多重动画绘制(multiple lines plot)
[bert、t5、gpt] 07 GPT2 decoding (greedy search, beam search)
[sbert 01] sentence-transformers pipeline
[动手写 bert] masking 机制、bert head 与 BertForMaskedLM
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[pytorch 网络拓扑结构] 深入理解 nn.LayerNorm 的计算过程
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[python 多进程、多线程] 03 GIL、threading、多进程,concurrent.futures
【机器学习中的数学】【概率论】正态分布的导数与拐点(inflection points)
[概率 & 统计] Thompson Sampling(随机贝叶斯后验采样)与多臂老虎机
[pytorch 模型拓扑结构] 深入理解 nn.BCELoss 计算过程及 backward 及其与 CrossEntropyLoss 的区别与联系
[AI 核心概念及计算] 概率计算 01 pytorch 最大似然估计(MLE)伯努利分布的参数
[pytorch optim] 优化器相关 AdaGrad(adaptive gradient) 与 RMSprop,自适应梯度
[PyTorch] Dropout 基本原理(前向计算与自动求导)
[动手写 bert 系列] bert model architecture 模型架构初探(embedding + encoder + pooler)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
[调包侠] 04 使用预训练模型进行图像特征向量提取(image feature extractor,img2vec)并进行相似性计算
[动手写Bert系列] bertencoder self attention 计算细节及计算过程