V
主页
京东 11.11 红包
CVPR'24 满分Oral | EscherNet 实现任意视角灵活扩散生成 解锁3D视觉无限可能!
发布人
EscherNet是一种多视角条件扩散模型,为视图合成提供了全新解决方案。它结合了隐式和生成式3D表示,通过创新的相机位置编码,实现了对多个参考视图和目标视图的精准控制,它可从少量参考视图生成超过100个一致的目标视图。与传统方法相比,EscherNet不仅节省了计算资源,在消费级GPU上也可运行。 标题:EscherNet: A Generative Model for Scalable View Synthesis 链接:https://kxhit.github.io/EscherNet
打开封面
下载高清视频
观看高清视频
视频下载器
超越BEVFusion!DifFUSER:扩散模型杀入自动驾驶多任务(BEV分割+检测双SOTA)
告别3DGS算法,开源SUNDAE,实现内存效率与图像质量的双赢
ECCV'24 最新Oral已开源 ! | 用于 3D大场景生成的金字塔扩散模型,实现无限场景生成与高效数据迁移
CVPR 2024 | LiDAR Diffusion 首个可以根据多模态条件生成逼真 的激光雷达场景方法,加速107倍
CVPR 2024 Highlight【清华、哈佛】|LangSplat:3D语言高斯溅射,告别模糊语言场,精准定义3D空间对象边界
ICRA 2024|Lightning NeRF:速度提升10倍!为自动驾驶场景而生
【李宏毅】2024年公认最好的扩散模型【Diffusion Model】教程!全程干货,通俗易懂,看完就跑通!-附带课件
Yann LeCun点赞转发,StableIdentity: 只需一张图片即可把任意 人像插入到任意场景中
CVPR'24 | NeRF新突破,启发式引导分割解决瞬态干扰
CVPR'24 Highlight 北大 | 扩展动态人景交互建模新突破, 生成的动作质量均优于现有技术
Gaussian-Flow:使用动态3D高斯粒子进行4D重建
腾讯XR实验室 | Sketch2Scene:”神笔马良”,你随意画的草图就可自动生成交互式3D游戏场景,且效果紧密契合你的意图
ECCV'24 | JHU提出无需SfM的X光3DGS技术: X-Gaussian,使得X射线新视图合成推理速度提升73倍!
ECCV'24 Oral | MVSplat:从稀疏多视图图像中实现高效的3DGS,用更少的参数,速度快2倍,还能跨数据集泛化
算法原理与代码实践融合讲解的NeRF精品课程之基础篇:体渲染
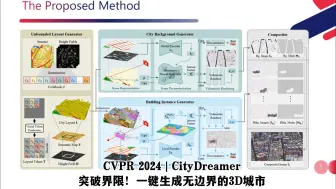
CVPR 2024 | CityDreamer突破界限!一键生成无边界的3D城市
什么是3D视觉无序抓取?
继3D高斯抛雪球法之后,4D高斯抛雪球模型问世,单视图视频也能快速生成动态3D对象了
谢赛宁惊呼:扩散模型训练方法,一直错了!!!
ECCV'24 NVIDIA | DiPIR:堪称"变色龙",可将3D物体无缝融合进各种场景,提升视觉真实感
双目摄像头三维重建
DiffTF:基于Transformer的大词汇量高质量 3D 物体生成框架,能够实现具有高度多样性、丰富语义和高质量的大词汇量3D物体生成。
CVPR2024 | SG-BEV:用于跨视图语义分割的卫星引导BEV融合,可实现精细的建筑属性分割
ECCV'24 开源 | 6DGS 又快又好,无需迭代的 单图像6D物体位姿估计
浙大TUM联合出品|Gaussian-LIC:首个LiDAR-IMU-Camera融合的3DGS-SLAM系统
Nature | 颠覆传统设计!电动液压肌肉骨骼机器人腿,实现真正意义上的灵活、强适应性的且节能运动!
视觉惯性-压力SLAM:水下考古遗址在线稠密三维重建
CVPR 2024 | 进一步加速落地:压缩自动驾驶端到端运动规划模型,PlanKD:一种为压缩端到端运动规划器量身定制的知识蒸馏方法
ECCV'24 oral | DVLO,首个基于深度聚类的多模态融合,双向结构对齐的融合网络新SOTA
鲁鹏老师精心打磨的NeRF基础与常见算法解析课程小节:神经网络与位置编码
刚刚不久,Apple 推出 Depth Pro AI – 3D 视觉的游戏规则改变者!
CVPR2024 | RCBEVDet:毫米波雷达-相机在BEV空间下的融合方案
黑神话·悟空爆火,有哪些AI技术在助力?
【完整版3D点云】学不会UP下跪!这是绝对是我看过最强的三维点云+三维重建实战教程!点云算法与NeuralRecon配置解读 计算机博士一次性给我教明白了!
三维重建入门到精通,30分钟教你学会运动恢复结构SFM
Cosplay.63【裸眼3D/平行眼】
使用 Isaac Sim 和 Isaac ROS 实现 AMR 视觉导航
梅卡曼德3D视觉引导高亮反光轴棒无序抓取
苏黎世联邦理工学院提出文本驱动运动控制扩散模型DART(今日Arxiv 10月8日)2024年10月8日Arxiv cs.CV发文量约186余篇
被2018年图灵奖得主Yann LeCun主动宣传的从文生连环画的生成模型,StoryDiffusion:用于长距离 图像和视频生成的一致性自注意力