V
主页
[Diffusion进展,文本转视频]新加坡国立大学、腾讯ARC实验室提出Tune-A-Video,使用文本生成图片模型One-Shot精调至视频,效果很棒
发布人
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation Jay Zhangjie Wu (Show Lab,新加坡国立大学),Yixiao Ge(腾讯ARC Lab),Xintao Wang(Show Lab,新加坡国立大学), Stan Weixian Lei(Show Lab,新加坡国立大学), Yuchao Gu(Show Lab,新加坡国立大学), Wynne Hsu(新加坡国立大学), Ying Shan(腾讯ARC Lab), Xiaohu Qie (腾讯PCG), Mike Zheng Shou(新加坡国立大学) 项目主页:https://tuneavideo.github.io/ Github主页:https://github.com/showlab/Tune-A-Video 为了延续文本到图片(T2I)生成的成功,近期在文本到视频(T2V)的生成使用了大规模的文本到视频的数据集进行精调。然后,这样的方法计算复杂度非常高。人类是有非常棒的能力来从单一的案例中学习这些视觉概念的。我们这里研究了一种新的T2V的生成问题,一个One-Shot视频生成方法,在仅有一个文本-视频对的情况下,训练一个开放的T2V生成器。我们采用了在大量图片数据预训练的T2I扩散模型来用在T2V的合成中,其中有两个主要的观察:1. T2I模型可以生成与动词对齐效果很好的图片 2. 扩展T2I模型来生成同时多张图片的效果非常意外的效果非常一致,质量也很好。为了进一步学习连续的动作,我们提出了剪裁过的Sparse-Causal Attention来构建Tune-A-Video,它可以通过在预训练的T2I扩散模型上,通过一个有效的one-shot调优,从文本输入生成视频。Tune-A-Video可以生成时域一致性非常好的视频,也可以用在如更换视频主题与背景、属性编辑、风格转换等多种应用场景中非常有效。这也显示出我们的模型的灵活性与有效性。 To reproduce the success of text-to-image (T2I) generation, recent works in text-to-video (T2V) generation employ large-scale text-video dataset for fine-tuning. However, such paradigm is computationally expensive. Humans have the amazing ability to learn new visual concepts from just one single exemplar. We hereby study a new T2V generation problem—One-Shot Video Generation, where only a single text-video pair is presented for training an open-domain T2V generator. Intuitively, we propose to adapt the T2I diffusion model pretrained on massive image data for T2V generation. We make two key observations: 1) T2I models are able to generate images that align well with the verb terms; 2) extending T2I models to generate multiple images concurrently exhibits surprisingly good content consistency. To further learn continuous motion, we propose Tune-A-Video with a tailored Sparse-Causal Attention, which generates videos from text prompts via an efficient one-shot tuning of pretrained T2I diffusion models....
打开封面
下载高清视频
观看高清视频
视频下载器
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[3D生成] 南洋理工、香港中文、上海AI实验室提出DiffTF,一个基于扩散模型和三平面的前馈框架,用于生成多样化的、大语料量规模的真实世界3D物体
[Diffusion进展,文本生成360度体验] Intel提出LDM3D,使用文本生成RGBD图,并将RGBD图渲染为360度三维体验感内容
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
生化环材研究生必看! 材料测试仪器实操第4期-X射线衍射仪。包含仪器介绍 样品制备 样品测试 数据导出~
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
[单图生成3D] UCSD, UCLA, 浙大, 康奈尔等:One-2-3-45,Zero123+SDF,超快速生成3D且几何一致性高,图片或文本生成高质量3D
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,带纹理的Mesh重建] 北京大学、百度提出NeRF2Mesh,优化现有Mesh重建方法,达到更好的Mesh效果、实时的渲染效果和后期处理能力
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
建筑设计作品集代做:NUS新加坡国立建筑作品集“滨城可持续渔村改造设计”
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[数据集] 上海AI实验室、商汤等提出DNA-Rendering,一个多样化的,高精度,以人物为中心的,包含2D/3D人体关键点,前景mask等大规模人体数据集
[Generative AI进展]Adobe,特拉维夫大学,CMU提出一种使用已训练生成模型和目标概念,直接生成目标域内容的方法,可批量生成大量效果
[NeRF纹理生成,SIGGRAPH] 中科院,腾讯等提出NeRF-Texture,从多视角图像采集和生成纹理,可应对如草、叶子、纺织品等3D空间复杂纹理生成
[NeRF+Diffusion进展] nVidia,多伦多大学等推出NeuralField-LDM,使用神经场和生成模型解决复杂开放世界3D场景的建模和编辑能力
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展] Oppo, Buffalo, 上科大提出NeuRBF,使用自适应的RBF进行神经场表达,相比INGP, TensoRF等取得更好的渲染效果
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[NeRF进展,few-shot重建,群友工作] UCLA, nVidia提出FreeNeRF,一个关键观察触发了一个极简的优化,使少量视角重建效果大幅度提升
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
基于SVD首尾帧进行关键帧插值,进行视频生成
【讨论班】生成式扩散模型综述
[SAM应用] CV不仅没有终结,而是更强了,新加坡国立大学LVLAB展示通过SAM+其他技术,实现Anything-3D,大模型的基础上,下游应用值得重来一次
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
与 Pony Diffusion XL V6 的作者的访谈 // Civitai 客座创作者
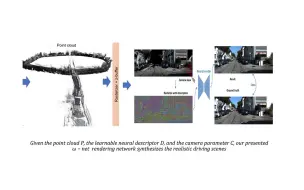
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)