V
主页
ECCV2022 | Box2Mask:强!mAP-50达到全监督97%!
发布人
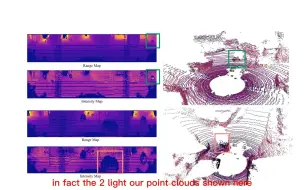
原文标题:Weakly Supervised 3D Semantic Instance Segmentation Using Bounding Boxes 论文链接:https://arxiv.org/pdf/2206.01203.pdf mAP50达到全监督97%!受经典Hough投票启发的深度模型,直接对边界框参数进行投票。 关注【自动驾驶之心】,优质原创不停歇! 回复【领域综述】获取自动驾驶全栈近80篇综述论文! 回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文! 回复【数据集下载】获取计算机视觉近30种数据集!
打开封面
下载高清视频
观看高清视频
视频下载器
ECCV2022 | DynamicDepth:无监督多帧单目深度的目标运动和遮挡分离
CVPR2022 oral | 弱监督Lidar点云分割SOTA!8% 标注数据下达到 95.7% 的全监督性能!
【IROS 2022】超大规模环视鱼眼数据集!SynWoodScape:8万张图像,十多个任务标注(检测/分割/深度/光流/事件等)
【ICCV 2023】 Robust Depth:多种天气条件下的自监督单目深度估计新SOTA
ECCV2024 | 训练45秒,渲染300+FPS!MVSGaussian:高效且可泛化的混合高斯渲染方法
ECCV2022最新 | 缺少点云数据?LiDARGen生成真实的激光雷达点云
【ECCV2022】首篇完全可微NeRF!Neural-Sim:学习使用NeRF生成训练数据(微软)
CVPR2022 | MeMOT:具有记忆的多目标跟踪
SOTA!ECCV2022 | 实现精确的主动相机定位(Camera Localization)
速度超快!激光雷达序列的在线分割:数据集和算法(ECCV2022)
【ECCV2022】自监督新SOTA!加速4倍!点云上自监督学习的Masked Discrimination
ICCV 2023 | NeO 360: 用于户外场景稀疏视图合成的神经场
【地平线×自动驾驶之心】ICCV 2023最新中稿的端到端自动驾驶框架—VAD!
ECCV2022 | ViT到底有多少种玩儿法?ViT-V2X:协同感知与ViT的首次碰撞会有怎样的火花?
端到端算法有哪些优势?完爆传统感知规控?
【ECCV 2022】Google最新视觉主干MaxViT大放异彩:分类准确率再创新高
Waabi最新!UnO:用于感知和预测的SOTA模型(超越监督方式)
CVPR 2023 | Mask DINO:面向检测和分割的统一Transformer最强框架!
BEVCar:SOTA!RV融合完成地图和分割双任务
StradVision - 语义分割和深度图预测demo
端到端算法是什么?自动驾驶领域是怎么做的?
ECCV2022 workshop | 自动驾驶中的自监督学习part2(数据处理、深度估计、3D检测/跟踪、SLAM、定位等!)
OmniDet:环视鱼眼多任务感知网络(深度估计、视觉里程计、语义和运动分割、目标检测和镜头污染检测)
【ECCV 2022】清华大学&字节跳动提出 ParticleSfM:从单目视频中估计运动相机的位姿
ECCV2022 workshop | 自动驾驶中的自监督学习part1(数据处理、深度估计、3D检测/跟踪、SLAM、定位等!)
ICLR 2023 |VA-DepthNet:单目图像深度预测的变分方法
【ECCV 2022】显著减少自动驾驶碰撞率!可微分光线投射应用于自监督占位预测
【IROS2022】Voxfield:用于在线规划和三维重建的非投影符号距离场
Transformer分割检测大模型技术分享:Transformer基础
毫米波雷达视觉算法CRAFT,这次彻底理解了!
TPVFormer:特斯拉occupany network的学术替代方案!清华大学工作
上海AI Lab最新!Depth any Video:提升深度估计的一致性以及合成更多真实带有标注的数据
决策规划都有哪些框架?PNC今年的香饽饽!近10种规控算法与代码实现你都知道吗?
KITTI SOTA!即插即用,单目3D检测中的单应性损失!(CVPR2022)
什么是端到端自动驾驶?什么是基础world model?
自动驾驶缺少数据怎么办?ChatSim助你生成高度真实的驾驶数据!
白天图像变夜晚数据SOTA方法| ManiFest:图像翻译新思路!(ECCV2022)
自动驾驶多传感器数据融合(1):什么是多传感器融合?
端到端自动驾驶:SparseDrive 算法详解
幼儿园小宝宝 都会的 3DSlicer TotalSegmentor分割一切教程,超简单版本