V
主页
CVPR 2023 | Mask DINO:面向检测和分割的统一Transformer最强框架!
发布人
实例分割、语义分割、全景分割新SOTA! 开源链接:https://github.com/IDEACVR/MaskDINO
打开封面
下载高清视频
观看高清视频
视频下载器
牛津大学最新!室内室外SOTA | 用于视觉重定位的地图相对姿态回归(CVPR'24 HighLight)
Segment Anything之后,分割的路在何方?
OmniDet:环视鱼眼多任务感知网络(深度估计、视觉里程计、语义和运动分割、目标检测和镜头污染检测)
适用任意相机模型!高通提出的BEV分割框架DaF-BEVSeg来了
CVPR 2023 面向自动驾驶场景的纯视觉三维语义占有预测
Segment Any Point Cloud:运用视觉基础模型分割一切点云
终生SLAM框架!BioSLAM:用于一般地点识别的仿生终身记忆系统
【全463集】禁止自学走弯路!环境感知、目标检测、语义分割、强化学习、决策与控制算法等八大自动驾驶核心算法一口气学完!
太详细了!多传感器融合的策略和方法
CVPR2022 | SHIFT:当前自动驾驶最大的多任务合成数据集(雾天/雨天/雪天,检测、分割、深度图、实例分割、光流)
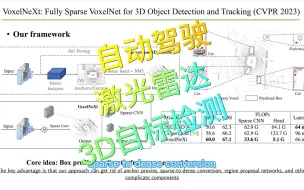
CVPR 2023:VoxelNeXt:用于3D目标检测和跟踪的全稀疏新框架!
端到端算法是什么?自动驾驶领域是怎么做的?
视觉3D检测如何做自动标注?
系统回顾!基于Visual Transformer的分割模型综述
TensorRT部署车道线检测最强算法!Ultra-Fast-Lane-Detection-V2
BEVFusion:一个简单而鲁棒的Lidar-Camera融合框架
【ICCV 2023】HAMLET:实时语义分割域自适应方法
CVPR'23 | OCTraN:非结构化交通场景中的3D占用卷积Transformer网络
什么是端到端自动驾驶?什么是基础world model?
【地平线×自动驾驶之心】ICCV 2023最新中稿的端到端自动驾驶框架—VAD!
Transformer分割检测大模型技术分享:Transformer基础
【三维重建】Semantic Gaussians:开放词汇的3DGS场景理解
2022最新 | HybridNets:端到端感知网络(检测+可行使区域分割+车道线三大任务)
渲染速度提高5倍!GaussianOcc:借助3D GS,没有标注也能做Occ(东京大学)
CVPR2022 oral | 弱监督Lidar点云分割SOTA!8% 标注数据下达到 95.7% 的全监督性能!
【IROS2022】联合学习结合语义分割!啪!泛化性这不就来了么~
ETH最新!CVPR2024 | GoMVS:多视图几何重建新SOTA
几可乱真!面向真实场景的世界模型居然被用得这么六!
ECCV2022 | Box2Mask:强!mAP-50达到全监督97%!
Depth Anything V2 | 速度提升10倍以上!更稳健、精细的单目深度估计(HKU&TikTok)
ICRA2023 | 激光雷达相机内外参联合标定方案!
Stable Diffusion建筑AI绘图教程 | AI如何用语义分割图 / 线稿精准生成城市鸟瞰图?
基于交互感知的自动驾驶车辆轨迹规划——神经网络与模型预估计控制的集成
【NeurIPS 2023】自动驾驶多模态感知蒸馏新方案来了!
牛的!大佬是如何几分钟聊透时空联合规划框架的?
yolo v11 | Detect Head 检测头
端到端趋势下,传统规控还有未来么?
刷爆!【深度学习-图像分割】图像分割+语义分割Unet原理讲解及项目实战教程!(人工智能、神经网络、机器学习、机器学习算法、Unet论文、Unet医学)
太强了!RenderOcc:仅使用2D标签和Nerf监督视觉Occupancy
速度超快!激光雷达序列的在线分割:数据集和算法(ECCV2022)