V
主页
华科&地平线最新!Senna:连接视觉语言模型与端到端自动驾驶
发布人
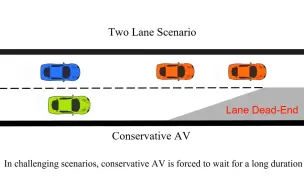
端到端自动驾驶系统凭借大规模数据展现出了强大的规划能力,但在复杂且罕见的场景中,由于常识的局限性,仍面临挑战。相比之下,大型视觉-语言模型(LVLMs)在场景理解和推理方面表现出色。未来的发展方向在于融合这两种方法的优势。以往使用LVLMs来预测轨迹或控制信号的方法效果不佳,因为LVLMs并不适合进行精确的数值预测。本文提出了一种名为Senna的自动驾驶系统,该系统将LVLM(Senna-VLM)与端到端模型(Senna-E2E)相结合。Senna将高级规划与低级轨迹预测相分离。Senna-VLM以自然语言生成规划决策,而Senna-E2E则预测精确的轨迹。Senna-VLM采用多图像编码方法和多视图提示来实现高效的场景理解。此外,我们还引入了面向规划的问答(QA)和三阶段训练策略,在保持常识的同时提升了Senna-VLM的规划性能。在两个数据集上的大量实验表明,Senna实现了最先进的规划性能。特别是,在大型数据集DriveX上进行预训练并在nuScenes上进行微调后,Senna相较于未进行预训练的模型,平均规划误差降低了27.12%,碰撞率降低了33.33%。我们认为Senna的跨场景泛化能力和迁移性对于实现完全自动驾驶至关重要。代码和模型将在https://github.com/hustvl/Senna上发布。
打开封面
下载高清视频
观看高清视频
视频下载器
牛津大学最新!室内室外SOTA | 用于视觉重定位的地图相对姿态回归(CVPR'24 HighLight)
太强了!RenderOcc:仅使用2D标签和Nerf监督视觉Occupancy
端到端趋势下,传统规控还有未来么?
什么是端到端自动驾驶?什么是基础world model?
【地平线×自动驾驶之心】在线高精矢量化地图构建SOTA方案MapTR v1/v2、LaneGAP
视觉3D检测如何做自动标注?
【地平线×自动驾驶之心】ICCV 2023最新中稿的端到端自动驾驶框架—VAD!
清华大学最新!GaussianFormer:Gaussians进军视觉Occupancy任务!
2022最新!Nvidia完整阐释自动驾驶中的视觉感知(超赞技术)
最新!如何使用深度强化学习在未知环境中进行导航?
端到端自动驾驶:SparseDrive 算法详解
基于交互感知的自动驾驶车辆轨迹规划——神经网络与模型预估计控制的集成
LeTS-Drive:自动驾驶中不确定场景下的实时路径规划算法
讲明白了!端到端算法评估指标详解
地平线最新SOTA!Sparse4D:迈向长时序稀疏化3D目标检测的新实践
端到端算法有哪些优势?完爆传统感知规控?
今年的智驾只有一个声音:端到端+大模型
从0到1!彻底搞懂BEVFormer算法原理
Segment Any Point Cloud:运用视觉基础模型分割一切点云
专注于学习PnC的端到端方法详解
为什么说规划控制仍然是端到端自动驾驶的核心?全面复盘规划控制基础及决策规划框架
都在聊大模型,那怎么评价多模态大模型的好坏呢?
决策规划都有哪些框架?PNC今年的香饽饽!近10种规控算法与代码实现你都知道吗?
新时代降临!多模态大模型的结构范式都有啥?
CVPR2023最新!TBP Former:BEV下以视觉为中心的自动驾驶中的联合感知和预测网络
自动驾驶规划控制的未来是什么?
毫米波雷达视觉到底是怎么融合的?CenterFusion你搞懂了吗?
【全网首讲】大佬开讲:我们是否走在开环端到端自动驾驶正确的道路上?
还在为数据集发愁?!带你了解自动驾驶常见数据集哪里找!
上交&诺亚最新 | 大幅提升!OccGen:面向自动驾驶的生成式多模态3D占用预测
上海AI Lab最新!Depth any Video:提升深度估计的一致性以及合成更多真实带有标注的数据
毫米波雷达视觉算法CRAFT,这次彻底理解了!
VastGaussian:首个基于3D Gaussian Splatting的大场景高质量重建和实时渲染方法
自动驾驶中的多传感器融合都有哪些方法?基本流程都是什么?
英伟达最新!Cube-LLM:通过视觉语言模型,真正感知3D世界
看完缓解了我的技术焦虑!自动驾驶的产线标定以及标定间标定方法
Nerf+SLAM会擦出什么样的火花?
自动驾驶仿真大观:聊聊仿真的研究背景
面试必备!自动驾驶中BEV常考知识点大串讲
特斯拉的World Model是什么?怎么做端到端训练?